opencv图像算法
图像
低通滤波
邻域滤波
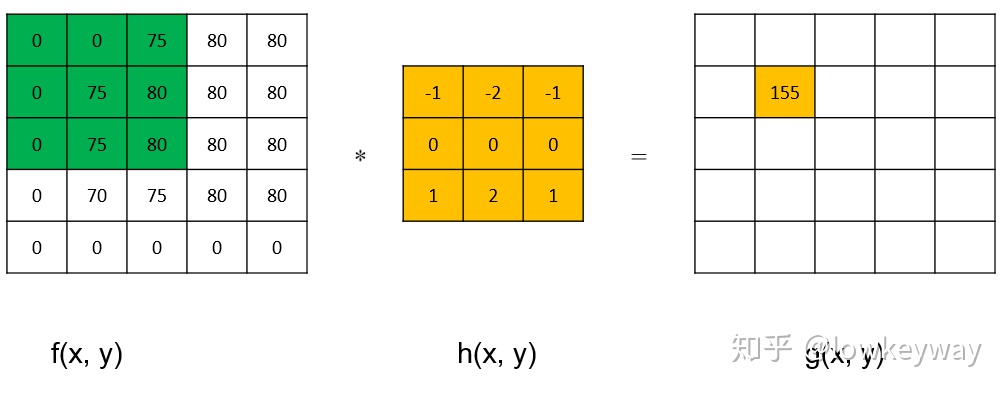
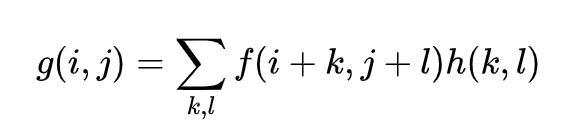
中值滤波
图像的中值滤波是一种非线性图像处理方法,是统计排序滤波器的一种典型应用。中值滤波是通过对邻域内像素按灰度排序的结果决定中心像素的灰度。具体的操作过程如下:用一个奇数点的移动窗口,将窗口中心点的值用窗口内各点的中值代替。假设窗口内有5个点,其值为1,2,3,4和5,那么此窗口内各点的中值即为3,也就是用3来代替中心点的像素值。
中值滤波对于滤除脉冲干扰及图像扫描噪声最为有效,还可以克服线性滤波器(如领域简单平滑滤波)带来的图像细节模糊。
数字图像存在冗余信息,具体分为六大冗余:空间冗余、时间冗余、视觉冗余、信息熵冗余、结构冗余、知识冗余。其中第一个空间冗余就可以很好的解释中值滤波的作用。空间冗余指的是:图像内部相邻像素之间存在较强的相关性而造成的冗余。简单来说就是,同一景物表面上采样点的颜色之间通常存在着空间相关性,相邻各点的取值往往相近或者相同,这就是空间冗余。而脉冲噪声通常是在一个邻域内有一个点或多个点的灰度值很高或很低,这就与周围像素存在较大差异,因此中值滤波能很好的去除这种噪声。
需要注意的是,中值滤波的窗口形状和尺寸对滤波效果影响很大,不同的图像内容和不同的应用要求,往往采用不同的窗口形状和尺寸。常用的中值滤波窗口有线状、方形、圆形、十字形以及圆环形等等。窗口尺寸一般先用3x3,再取5x5逐渐增大,直到滤波效果满意为止。就一般经验来讲,对于有缓变的较长轮廓线物体的图像,采用方形或圆形窗口为宜。对于包含有尖顶物体的图像,用十字形窗口,而窗口大小则以不超过图像中最小有效物体的尺寸为宜。如果图像中点、线、尖角细节较多(感觉就是邻域灰度值变化较大),则不宜采用中值滤波。
自适应中值滤波
上面提到常规的中值滤波器,在噪声的密度不是很大的情况下,效果不错。但是密度较高时,常规的中值滤波的效果就不是很好了。有一个选择就是增大滤波器的窗口大小,这虽然在一定程度上能解决上述的问题,但是会给图像造成较大的模糊。
常规的中值滤波器的窗口尺寸是固定大小不变的,就不能同时兼顾去噪和保护图像的细节。这时就要寻求一种改变,根据预先设定好的条件,在滤波的过程中,动态的改变滤波器的窗口尺寸大小,这就是自适应中值滤波器 。在滤波的过程中,自适应中值滤波器会根据预先设定好的条件,改变滤波窗口的尺寸大小,同时还会根据一定的条件判断当前像素是不是噪声,如果是则用邻域中值替换掉当前像素;不是,则不作改变。
自适应中值滤波器有三个目的:
- 滤除椒盐噪声
- 平滑其他非脉冲噪声
- 尽可能的保护图像中细节信息,避免图像边缘的细化或者粗化。
实现过程:
对于每一个像素点的处理,使用一个while循环。在while循环中:
首先,在当前像素点下根据当前尺寸窗口的大小获取数据存入数组;
其次,获取窗口内像素的最大最小值和中值;
再,得到A1(中值 - 最小值),A2(中值 - 最大值)。
预先定义好以下符号:
Sxy: 滤波器的作用区域,滤波器窗口所覆盖的区域;
Zmin: Sxy中最小的灰度值;
Zmax: Sxy中最大的灰度值;
Zmed: Sxy中所有灰度值的中值;
Zxy: 表示图像中对应像素点的灰度值;
Smax: Sxy所允许的最大窗口尺寸;
自适应中值滤波器分为以下两个过程,A和B:
A:
- A1 = Zmed - Zmin
- A2 = Zmed - Zmax
- 如果A1>0 且 A2<0,则跳转到B
- 否则,增大窗口的尺寸
- 如果增大后的尺寸 ≤ Smax,则重复A
- 否则,直接输出Zmed
B:
- B1 = Zxy - Zmin
- B2 = Zxy - Zmax
- 如果B1>0 且 B2<0,则输出Zxy
- 否则输出Zmed
实现原理:
A步骤实质是判断当前区域的中值点是否是噪声点,通常来说是满足条件的,此时中值点不是噪声点,跳转到B;考虑一些特殊情况,如果Zmed=Zmin或者Zmed=Zmax,则认为是噪声点,应该扩大窗口尺寸,在一个更大的范围内寻找一个合适的非噪声点,随后再跳转到B,否则输出的中值点是噪声点;
接下来考虑跳转到B之后的情况:判断中心点的像素值是否是噪声点,原理同上,因为如果Zxy=Zmin或者Zxy=Zmax,则认为是噪声点。如果不是噪声点,我们可以保留当前像素点的灰度值;如果是噪声点,则使用中值替代原始灰度值,滤去噪声。
均值滤波
一种特殊形式的邻域滤波(邻域算子都是1/M*N)。
图片中一个方块区域(一般为3*3)内,中心点的像素为全部点像素值的平均值。均值滤波就是对于整张图片进行以上操作。
缺陷:均值滤波本身存在着固有的缺陷,即它不能很好地保护图像细节,在图像去噪的同时也破坏了图像的细节部分,从而使图像变得模糊,不能很好地去除噪声点。特别是椒盐噪声
算术均值滤波
这是最简单的均值滤波器,可以去除均匀噪声和高斯噪声,但会对图像造成一定程度的模糊。
算术均值滤波器就是简单的计算窗口区域的像素均值,然后将均值赋值给窗口中心点处的像素:
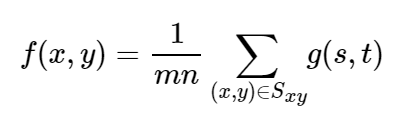
其中,g(s,t)表示原始图像,f(x,y)表示均值滤波后得到的图像,Sxy表示滤波器窗口。
基于上述公式,可以很容易的得到的算术均值滤波器的窗口模板,下面以3×3为例:
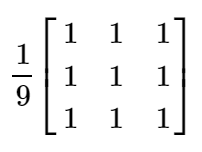
几何均值滤波
滤波后图像的像素由模板窗口内像素的乘积的1/mn幂给出。 和算术均值滤波器相比,几何均值滤波器能够更好的取出高斯噪声,并且能够更多的保留图像的边缘信息。但其对0值是非常敏感的,在滤波器的窗口内只要有一个像素的灰度值为0,就会造成滤波器的输出结果为0。
公式如下:
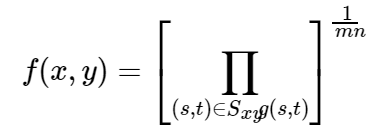
谐波均值滤波
对盐粒噪声(白噪声)效果较好,不适用于胡椒噪声;比较适合处理高斯噪声。
公式如下:
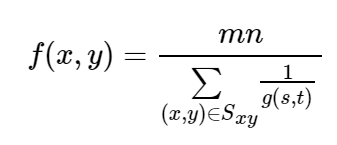
逆谐波均值滤波
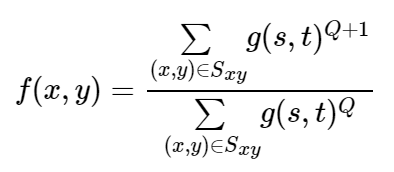
其中Q称为滤波器的阶数,该滤波器可以用来消除椒盐噪声。但是不能同时处理盐粒噪声和胡椒噪声,当Q为正时,可以消除胡椒噪声;当Q为负时,消除盐粒噪声。当Q=0时,该滤波器退化为算术均值滤波器;Q=-1时,退化为谐波均值滤波器。
修正后的alpha均值滤波
假设在Sxy模板领域内,去掉g(s,t)中最高灰度值的d/2和最低灰度值的d/2个像素。用gr(s,t)来代替剩余的mn-d个像素。由剩余像素点的平均值形成的滤波器称为修正后的alpha均值滤波器:
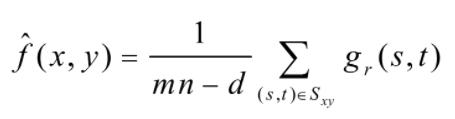
其中d取0~m*n-1之间的任意数。
当d=0时,退变为算术均值滤波;
当d=(m*n-1),退变为中值滤波器;
d取其他值时,该滤波器适用于包括多种噪声的情况,如高斯噪声和椒盐噪声混合的情况。
基于局部均方差的图像去噪
设x(i,j)为模板中心的灰度值,那么在(2n+1)x(2m+1)的窗口内,其局部均值可以表示为
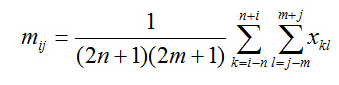
其局部均方差可以表示为:
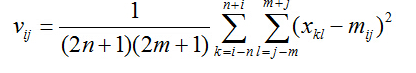
加性去噪后的结果为,其中 σ 为输入值:
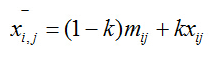
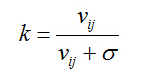
方差在统计学中表示的是与中心偏离的程度,用来衡量数据的波动性大小。对于图像而言,当上述局部方差比较小,意味着图像中该局部区域属于灰度平坦区,各个像素灰度值相差不大;相反,当上述局部方差比较大的时候,意味着图像中该局部区域属于边缘或者是其他高频部分区域,各个像素的灰度值相差比较大。
当局部属于平坦区时,方差很小,趋近于0。该点滤波之后的像素就是该点的局部平均值。由于该局部各点像素的灰度值相差不大,其局部平均值也与各个像素的灰度值相差不大;当局部属于边缘区域时,方差较大,相对于用户输入的参数可以基本忽略不计,其图像去噪之后,就等于输入的图像灰度值。
这种方法在一定程度上对边缘具有保留,能够保留边缘的同时,进行去噪。
本质上是一个动态均值滤波的过程,在边缘处(即方差较大区域)尽量保留原值,而在平坦处尽量执行均值滤波。
最值滤波
最大值和最小值滤波
最值滤波就是取kernal排序后得最大值或最小值来取代中心像素作为输出。
分为最大值滤波和最小值滤波,分别相当于形态学操作的膨胀和腐蚀。
中点滤波
在上述最值滤波的基础上,取最大值和最小值的平均值作为中心像素点的输出。
双边滤波
双边滤波是一种非线性滤波器,它可以达到保持边缘、降噪平滑的效果。和其他滤波原理一样,双边滤波也是采用加权平均的方法,用周边像素亮度值的加权平均代表某个像素的强度,所用的加权平均基于高斯分布[1]。最重要的是,双边滤波的权重不仅考虑了像素的欧氏距离(如普通的高斯低通滤波,只考虑了位置对中心像素的影响),还考虑了像素范围域中的辐射差异(例如卷积核中像素与中心像素之间相似程度、颜色强度,深度距离等),在计算中心像素的时候同时考虑这两个权重。它是一种可以保边去噪的滤波器。之所以可以达到此去噪效果,是因为滤波器是由两个函数构成。一个函数是由几何空间距离决定滤波器系数。另一个由像素差值决定滤波器系数。
双边滤波的核函数是空间域核与像素范围域核的综合结果:在图像的平坦区域,像素值变化很小,对应的像素范围域权重接近于1,此时空间域权重起主要作用,相当于进行高斯模糊;在图像的边缘区域,像素值变化很大,像素范围域权重变大,从而保持了边缘的信息。
空间域公式如下:
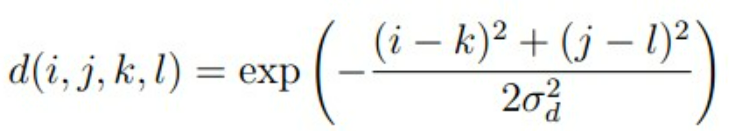
像素范围域(颜色域)公式如下:
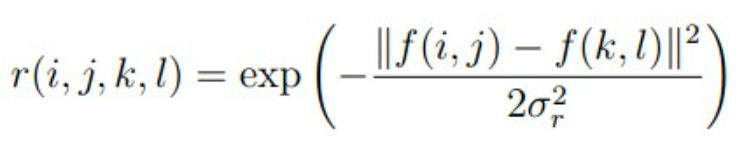
他们的乘积即为双边滤波的权重:
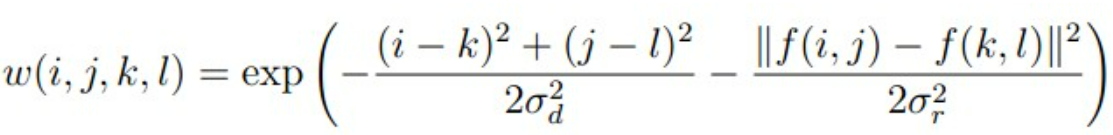
根据权重计算最后目标点的像素值:
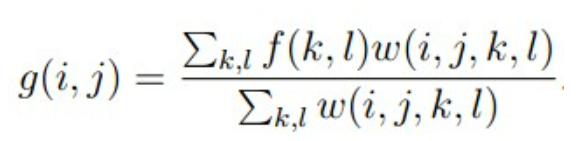
高斯滤波
高斯滤波器是一种线性滤波器,能够有效的抑制噪声,平滑图像。其作用原理和均值滤波器类似,都是取滤波器窗口内的像素的均值作为输出。其窗口模板的系数和均值滤波器不同,均值滤波器的模板系数都是相同的为1;而高斯滤波器的模板系数,则随着距离模板中心的增大而系数减小。所以,高斯滤波器相比于均值滤波器对图像个模糊程度较小。
高斯滤波器
二维高斯函数如下:
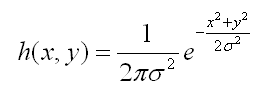
其中e前的参数可以忽略,因为这只是个表示幅值的常数,并不影响相互之间的比例关系,并且最终都要进行归一化,所以实际只需要计算后半部分即可。该参数仅影响图像的亮度而不影响模糊。
例如,要产生一个3×3的高斯滤波器模板,以模板的中心位置为坐标原点进行取样。模板在各个位置的坐标,如下所示(x轴水平向右,y轴竖直向下)
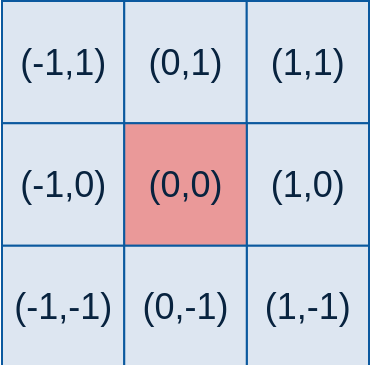
对于窗口模板的大小为 (2k+1)×(2k+1),模板中各个元素值的计算公式如下:
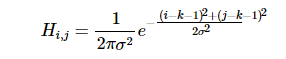
转化为代码:
for(int i = 0; i < m; ++i)
for(int j = 0; j < n; ++j)
double g = exp(((i - m/2)*(i - m/2) + (j - n/2)*(j - n/2)) * -1.0 / (2 * sigma * sigma));再对求出来的每个g进行归一化(因为求的是加权平均,要保证窗口模板各元素和为1)
kernel = g / sum;关于高斯分布的标准差σ的选值,代表着数据的离散程度。如果σ较小,那么生成的模板的中心系数较大,而周围的系数较小,这样对图像的平滑效果就不是很明显;反之,σ较大,则生成的模板的各个系数相差就不是很大,比较类似均值模板,对图像的平滑效果比较明显。
高斯分布的概率分布密度图如下:
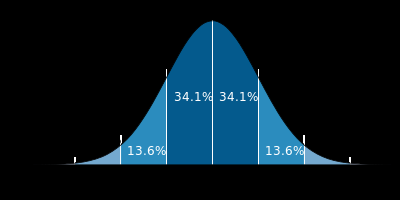
横轴表示可能得取值x,竖轴表示概率分布密度F(x),那么不难理解这样一个曲线与x轴围成的图形面积为1。σσ(标准差)决定了这个图形的宽度,可以得出这样的结论:σσ越大,则图形越宽,尖峰越小,图形较为平缓;σσ越小,则图形越窄,越集中,中间部分也就越尖,图形变化比较剧烈。这其实很好理解,如果sigma也就是标准差越大,则表示该密度分布一定比较分散,由于面积为1,于是尖峰部分减小,宽度越宽(分布越分散);同理,当σσ越小时,说明密度分布较为集中,于是尖峰越尖,宽度越窄!
以上求出来的就是模板系数,滤波操作就是分别以图像的每个像素点为中心再根据模板系数求出加权平均像素,作为该点的滤波后像素。比如3x3模板,对选中像素点的外一圈共九个像素点,分别乘以对应位置的模板系数再求和,即为选中点的像素。
高通滤波(边缘检测)
如何识别图像边缘?图里面有一条线,左边很亮,右边很暗,那人眼就很容易识别这条线作为边缘.也就是像素的灰度值快速变化的地方,那么如何来数学化这个问题,就是梯度。
- 要获得一幅图像的梯度,就需要在图像的每个像素点计算对x和对y的偏导数,也就是 **gx = f(x+1,y) - f(x,y) 和 gy = f(x,y+1) - f(x,y)**,转化为模板也就是,水平和垂直的 [-1,1] 模板。
- 而当我们对对角线方向的边缘感兴趣时,就产生了Roberts算子,原理就是把一维的模板斜过来。
- Roberts算子中2x2的模板在概念上很简单,但在实际应用中,它对于用关于中心点对称的模板来计算边缘方向不是很有用。相对来说3x3考虑了中心点对端数据的性质,并携带了关于边缘方向的更多信息。于是就产生了 Prewitt算子。它的3x3模板考虑到了水平/垂直和斜边的信息,相比于Roberts更准确。
- 在Prewitt的基础上,在卷积核的中心位置处使用2代替1,能较为有效的平滑图像,抑制噪声,这就是Sobel算子。而针对不同的需求,可以设计不同的卷积核,例如需要对对角线方向有更好的响应,那么可以将2设置在卷积核的两个对角。
Roberts算子
Roberts算子是一种最简单的算子,利用局部差分寻找边缘的算子。采用对角线相邻两像素之差近似梯度幅值检测边缘。检测垂直边缘的效果比斜向边缘要好,定位精度高,对噪声比较敏感,无法抑制噪声的影响。
Roberts边缘算子是一个2x2的模板,采用的是对角方向相邻的两个像素之差。从图像处理的实际效果来看,边缘定位较准,对噪声敏感。模板如下:
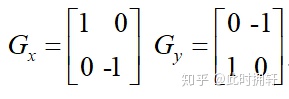
对于输入图像f(x,y),使用Roberts算子后输出的目标图像为g(x,y),则
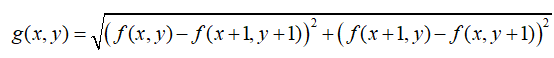
Sobel算子(一阶导数法)
基于寻找梯度强度
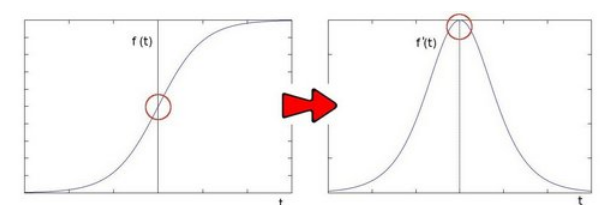
对于f(t),其导数f’(t)反映了每一处的变化趋势.在变化最快的位置其导数最大. sobel算子的思路就是模拟求一阶导数.
sobel算子是一个离散差分算子.它计算图像像素点亮度值的近似梯度。图像是二维的,即沿着宽度/高度两个方向。我们使用两个卷积核对原图像进行处理:
水平方向:
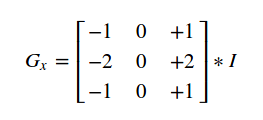
原始像素灰度值–>(右边像素值-左边像素值),反映了水平方向的变化情况.
垂直方向同理:
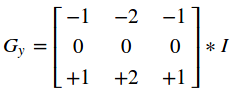
这样就得到了两个新的矩阵,分别反映了每一点像素在水平方向上的亮度变化情况和在垂直方向上的亮度变换情况。
综合考虑这两个方向的变化,使用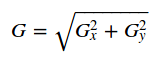 反映某个像素的梯度变化情况.
反映某个像素的梯度变化情况.
有时候为了简单起见,也直接用绝对值相加替代: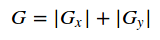
在opencv中也可以通过以下卷积核(Scharr)大像素的变化情况:
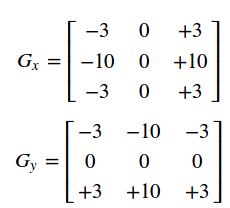
与滤波一样,对每个像素点的处理为:要操作像素点对应于Gx,Gy矩阵中心,对该像素点和周边9个像素点乘以相应系数求和,得到一个方向上的处理结果。完整的Sobel算子则需要对两个方向上的处理结果求和,得到完整的新像素值。
opencv的Sobel函数
1.采用了可分离的卷积核
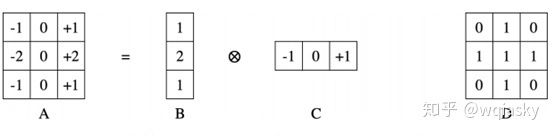
图A是可分离的;它可以表示为两个一维卷积(B和C);D是一个不可分割内核的例子。可分离的内核是可以被认为是两个一维的内核,首先与x内核进行卷积然后与y内核进行卷积来应用。这种分解的好处是内核卷积的计算成本大约是图像面积乘以内核区域。这意味着用n×n内核卷积区域A的图像需要时间与An2成正比,同时n×1内核与图像卷积一次,然后与1×n内核卷积占用与An + An = 2An成比例。
随着图像尺寸与卷积核尺寸的增大,用分离的卷积核依次对图像进行卷积操作,可以有效地提高运算速度。因此,在二维图像处理中,经常将一个可分离卷积核分解为一维水平核 kernalX 和一维垂直核 kernalY 的乘积。
秩为 1 的矩阵可以分解为一个列向量与一个行向量的乘积,因此秩为 1 的卷积核是可分离卷积核。
可分离卷积核 w 与图像 f 的卷积(same 卷积),等于先用 f 与 w1 卷积,再用 w2 对结果进行卷积:

2.行、列卷积核的生成
阅读源码:
for( int k = 0; k < 2; k++ ) // 分别生成行、列
{
Mat* kernel = k == 0 ? &kx : &ky;
int order = k == 0 ? dx : dy;
int ksize = k == 0 ? ksizeX : ksizeY; // ksize都是相同的
CV_Assert( ksize > order );
if( ksize == 1 )
kerI[0] = 1;
else if( ksize == 3 ) // 卷积核大小设为3时使用固定值
{
if( order == 0 )
kerI[0] = 1, kerI[1] = 2, kerI[2] = 1;
else if( order == 1 )
kerI[0] = -1, kerI[1] = 0, kerI[2] = 1;
else
kerI[0] = 1, kerI[1] = -2, kerI[2] = 1;
}
else // 大于3时进行计算,巧妙
{
int oldval, newval;
kerI[0] = 1;
for( i = 0; i < ksize; i++ )
kerI[i+1] = 0;
for( i = 0; i < ksize - order - 1; i++ )
{
oldval = kerI[0];
for( j = 1; j <= ksize; j++ )
{
newval = kerI[j]+kerI[j-1];
kerI[j-1] = oldval;
oldval = newval;
}
}
for( i = 0; i < order; i++ )
{
oldval = -kerI[0];
for( j = 1; j <= ksize; j++ )
{
newval = kerI[j-1] - kerI[j];
kerI[j-1] = oldval;
oldval = newval;
}
}
// 以上计算,假设ksize=5,order=1,可得一维核:[-1,-2,0,2,1]
}
}设ksize=3,dx=1,dy=0,带入运算可得:

卷积核的效果和二维的是相同的。
3.可分离卷积的计算
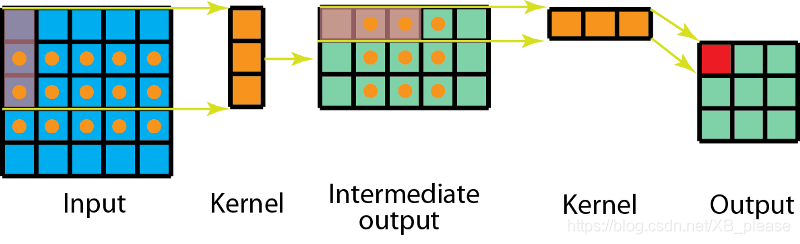
我们首先在5x5图像上用3x1卷积。这样的话卷积核就能横向扫描5个位置,纵向扫描3个位置,如上图所标的点所示。
现在得到的是一个3x5的矩阵,这个矩阵经过1x3卷积核的卷积操作——从横向上的 3 个位置以及纵向上的 3个位置来扫描该矩阵。
Prewitt算子
Prewitt算子的原理和sobel是一模一样的,唯一的区别就是卷积核存在差异:
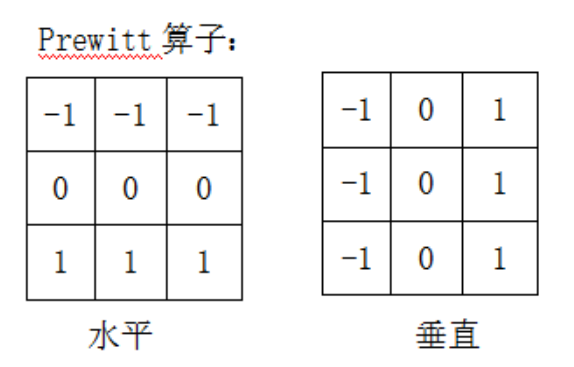
Sobel相较于Prewitt,在中心权值上使用2来代替1,这样可以较好的抑制噪声。
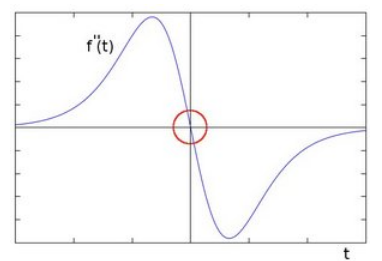
Laplacian算子(二阶微分法)
基于过零点检测
对Sobel算子中的一阶导数函数再次求导可得:
二阶差分公式: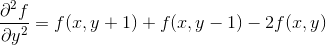
Laplace算子的差分形式:
分别对Laplace算子x,y两个方向的二阶导数进行差分就得到了离散函数的Laplace算子。在一个二维函数f(x,y)中,x,y两个方向的二阶差分分别为:
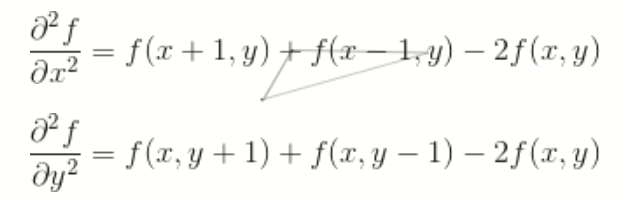
于是可得Laplace算子的差分形式为:
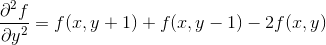
写作滤波模板的形式如下:
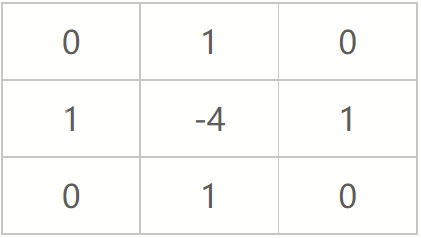
注意该模板的特点,在上下左右四个90度的方向上结果相同,也就是说在90度方向上无方向性。为了让该mask在45度的方向上也具有该性质,可以对该模板进行扩展定义为:
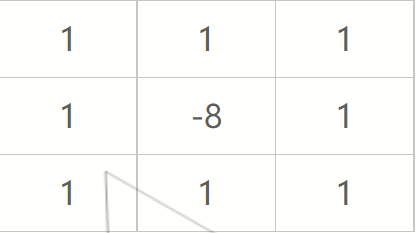
注:定义数字形式的拉普拉斯要求系数之和必为0。
之后的操作与其他的空间滤波操作相同。将模板在原图上逐行移动,然后模板中各系数与其重合的像素相乘后求和,赋给与mask中心重合的像素。
拉普拉斯对噪声敏感,会产生双边效果。不能检测出边的方向。通常不直接用于边的检测,只起辅助的角色,检测一个像素是在边的亮的一边还是暗的一边利用零跨越,确定边的位置。
Canny算子
图像边缘信息主要集中在高频段,通常说图像锐化或检测边缘,实质就是高频滤波。
微分运算是求信号的变化率,具有加强高频分量的作用。在空域运算中来说,对图像的锐化就是计算微分。由于数字图像的离散信号,微分运算就变成计算差分或梯度。
因此canny算子求边缘点分为以下四步:
1.使用高斯滤波器平滑图像
卷积的核心意义就是获取原始图像中像模板特征的性质。
2.用一阶偏导有限差分(Sobel)计算梯度值和方向
经典Canny算法用了四个梯度算子来分别计算水平,垂直和对角线方向的梯度。但是通常都不用四个梯度算子来分别计算四个方向。常用的边缘差分算子(如Rober,Prewitt,Sobel)计算水平和垂直方向的差分Gx和Gy。这样就可以如下计算梯度模和方向:
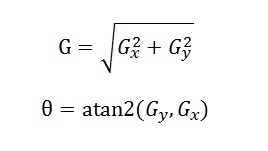
梯度角度θ范围从弧度-π到π,然后把它近似到四个方向,分别代表水平,垂直和两个对角线方向(0°,45°,90°,135°)。
由于图像的坐标系是以左上角为原点向右和下延展,因此根据像素点计算出的角度值必然在一、四象限。那么可以分别以 ± π / 8(水平) 、π / 8 ~ 3π / 8(45°)、- π / 8 ~ - 3π / 8(-45°)、一四象限剩余部分(垂直)来分割,落在每个区域的梯度角给一个特定值,代表四个方向之一。
3.对梯度幅值进行非极大值抑制
意义就是寻找像素点局部最大值。
沿着梯度方向,比较它前面和后面的梯度值即可(对于左右边界,则比较附近的两个值)。如果是最大值就保留,否则置为0。
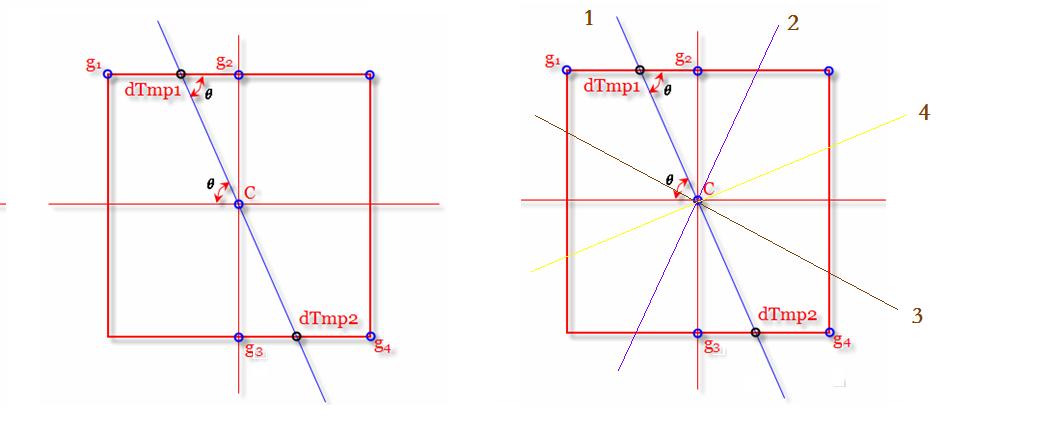
如上图,c点为需要判断的点,按照2中划分的四个区域,可以看到每个区域包含了八邻域中的两个点,通过判断c点的角度值所在区域,与该区域包含的那两个点进行比较即可。
若想提高精度,如上右图:c的角度值在π / 8 ~ 3π / 8(45°)区域,不比较g1和g4,而是比较dTmp1和dTmp2,由于这两个点都是浮点坐标,因此需要采用线性插值方法来计算这两个点的幅值。
通过角度θ可以计算出dTmp1在g1和g2之间的比例,设dis(dTmp1,g2) = w,则dis(g1,dTmp1) = 1 - w。所以dTmp1的幅值为:w * g2 + (1 - w)* g1。同理可得dTmp2的幅值。将c的幅值与这两个浮点坐标的幅值进行比较进行非极大值抑制。
4.用双阈值算法检测、连接边缘
一般的边缘检测算法用一个阈值来滤除噪声或颜色变化引起的小的梯度值,而保留大的梯度值。Canny算法应用双阈值,即一个高阈值和一个低阈值来区分边缘像素。如果边缘像素点梯度值大于高阈值,则被认为是强边缘点。如果边缘梯度值小于高阈值,大于低阈值,则标记为弱边缘点。小于低阈值的点则被抑制掉。
一般来说,建议高低阈值的比率为2:1或3:1
4.5.滞后边界跟踪
强边缘点可以认为是真的边缘。弱边缘点则可能是真的边缘,也可能是噪声或颜色变化引起的。为得到精确的结果,后者引起的弱边缘点应该去掉。通常认为真实边缘引起的弱边缘点和强边缘点是连通的,而又噪声引起的弱边缘点则不会。所谓的滞后边界跟踪算法检查一个弱边缘点的8连通领域像素,只要有强边缘点存在,那么这个弱边缘点被认为是真是边缘保留下来。
只需对所有被标记过的弱边缘点的八邻域进行遍历,若邻域中存在强边缘点,则保留;否则抑制掉。
方向算子
方向算子利用一组模板分别计算在不同方向上的差分值,取其中最大的值作为边缘强度,而将与之对应的方向作为边缘方向。
Kirsch算子
类似于Sobel算子,也利用图像中某点的梯度幅值作为像素的灰度值,Sobel算子计算出某点两个方向的梯度值,Gx、Gy;但Kirsch算子 利用8个卷积模板计算出了某点8个方向的梯度幅值和方向,并以最大的卷积值作为该点的灰度值。
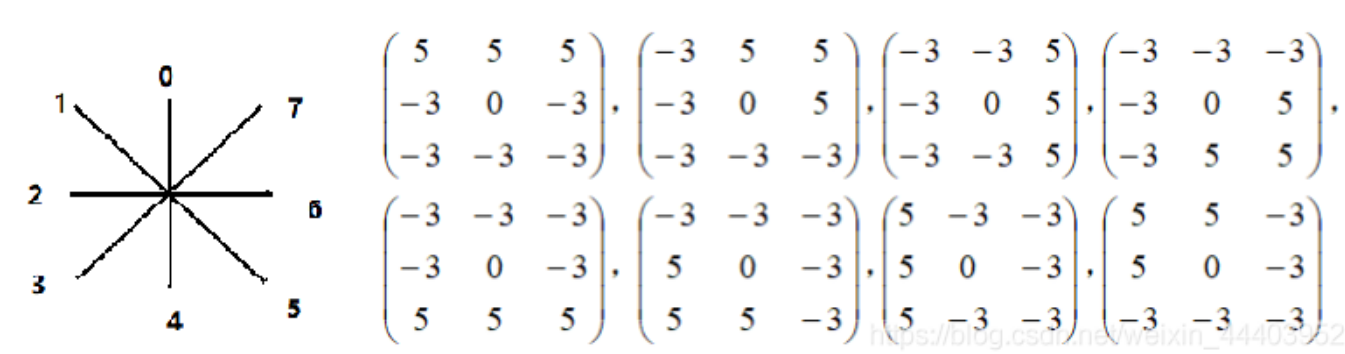
对每个像素点都用 这8个模板进行进行卷积(注意,每个卷积值都应取绝对值),求出该点的最大卷积值。
Nevitia算子
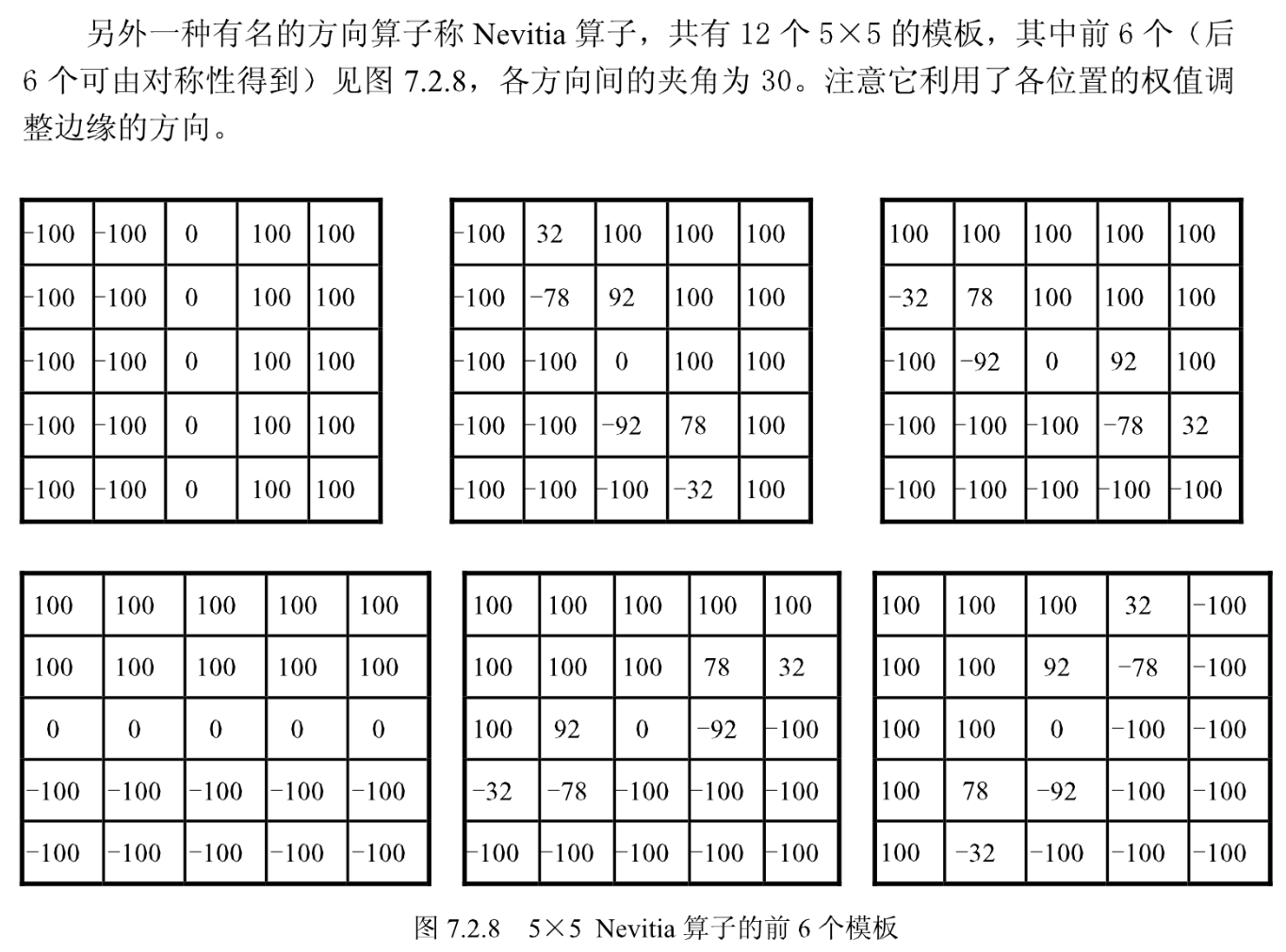
形态学
膨胀
膨胀的操作本质上来说和滤波是一样的,采用滑动窗口(为像素点指定邻域)的模式去遍历整张图,来调整像素值。
调整方式为:选取像素点及其指定邻域中的极大值,作为该像素点的新值。
膨胀同sobel一样存在方向性,可以通过改变邻域的形状,来控制膨胀的方向。
腐蚀
腐蚀与膨胀的原理相同。
调整方式为:选取像素点及其指定邻域中的极小值,作为该像素点的新值。
膨胀和腐蚀是针对图像中的高亮部分的变化来说的。
膨胀和腐蚀常用于二值图的操作。
连通域
连通域一般是指图像中具有相同像素值且位置相邻的前景像素点组成的图像区域。连通区域分析是指将图像中的各个连通区域找出并标记。通常连通区域分析处理的对象是一张二值化后的图像。
从连通域的定义可以知道,一个连通区域是由具有相同像素值的相邻像素组成像素集合,因此,我们就可以通过这两个条件在图像中寻找连通区域,对于找到的每个连通区域,我们赋予其一个唯一的标识(Label),以区别其他连通区域。
最常见的有两种算法:Two-pass法和Seed-Filling种子填充法。
种子填充法
本质上就是DFS,维护一个队列或者堆栈。
按照从上到下、从左到右的顺序遍历图像,对于找到的每一个为指定前景色且未被标记的像素点重复执行以下步骤:
1.标记该像素点,并将该点坐标入队。
2.开启DFS,while(队列非空)。
3.while内部,获取队首的坐标,并将其出队。搜寻该点的4邻域或8邻域(注意边界限幅),若存在为指定前景色且未被标记的像素点,标记并入队。
3.5 while中可维护变量用于统计该连通域的像素点数(面积)和x、y坐标的总和(求均值作为连通域的中心)。
代码实现
由于实际应用需求,写的是纯C的版本,没有队列向量,malloc了两个二维数组用来存取连通域信息。
unsigned char* flag = (unsigned char*)malloc(sizeof(unsigned char) * width * height);
memset(flag, 0, sizeof(unsigned char) * width * height);
int** con = (int**)malloc(sizeof(int*) * conNums);
int** conInfo = (int**)malloc(sizeof(int*) * conNums);
for (int i = 0; i < conNums; i++) {
// x、y点坐标
con[i] = (int*)malloc(width * height * sizeof(int) * 2);
// 区域信息 0-Area、12-Center、310-Rect
conInfo[i] = (int*)malloc(sizeof(int) * 11);
}
int conIdx = -1; // 标记连通域的序号
int ptr = 0; // 通过自加模拟出队
int growNum = 0; // 模拟队列是否为空
int sumx = 0, sumy = 0, curx = 0, cury = 0;
for (int i = 0; i < height; i++) {
for (int j = 0; j < width; j++) {
if (srcImage[i * width + j] == 255 && flag[i * width + j] == 0
&& conIdx < conNums - 1) {
// 初始化本次连通域信息
conIdx++;
growNum = 1;
ptr = 0;
sumx = 0;
sumy = 0;
flag[i * width + j] = conIdx + 1;
con[conIdx][0] = j;
con[conIdx][1] = i;
// 开找
while (growNum > 0) {
curx = con[conIdx][ptr++];
cury = con[conIdx][ptr++];
sumx += curx;
sumy += cury;
growNum--;
if (cury > 0 && srcImage[(cury - 1) * width + curx] == 255
&& flag[(cury - 1) * width + curx] == 0)
{
flag[(cury - 1) * width + curx] = conIdx + 1;
con[conIdx][ptr + growNum * 2] = curx;
con[conIdx][ptr + growNum * 2 + 1] = cury - 1;
growNum++;
}
if (cury < height - 1 && srcImage[(cury + 1) * width + curx] == 255
&& flag[(cury + 1) * width + curx] == 0)
{
flag[(cury + 1) * width + curx] = conIdx + 1;
con[conIdx][ptr + growNum * 2] = curx;
con[conIdx][ptr + growNum * 2 + 1] = cury + 1;
growNum++;
}
if (curx > 0 && srcImage[cury * width + curx - 1] == 255
&& flag[cury * width + curx - 1] == 0)
{
flag[cury * width + curx - 1] = conIdx + 1;
con[conIdx][ptr + growNum * 2] = curx - 1;
con[conIdx][ptr + growNum * 2 + 1] = cury;
growNum++;
}
if (curx < width - 1 && srcImage[cury * width + curx + 1] == 255
&& flag[cury * width + curx + 1] == 0)
{
flag[cury * width + curx + 1] = conIdx + 1;
con[conIdx][ptr + growNum * 2] = curx + 1;
con[conIdx][ptr + growNum * 2 + 1] = cury;
growNum++;
}
}
// 计算连通域的面积、中心点和最小外接矩
conInfo[conIdx][0] = ptr / 2;
if (conInfo[conIdx][0] < minConArea) { // 小于指定面积的连通域舍弃
conIdx--;
}
else {
conInfo[conIdx][1] = sumx * 2 / ptr;
conInfo[conIdx][2] = sumy * 2 / ptr;
int miny = 9999, maxy = 0, minx = 9999, maxx = 0;
for (int y = 0; y < conInfo[conIdx][0]; y++) {
if (con[conIdx][y * 2 + 1] < miny) miny = con[conIdx][y * 2 + 1];
if (con[conIdx][y * 2 + 1] > maxy) maxy = con[conIdx][y * 2 + 1];
if (con[conIdx][y * 2] < minx) minx = con[conIdx][y * 2];
if (con[conIdx][y * 2] > maxx) maxx = con[conIdx][y * 2];
}
conInfo[conIdx][3] = minx;
conInfo[conIdx][4] = maxy;
conInfo[conIdx][5] = minx;
conInfo[conIdx][6] = miny;
conInfo[conIdx][7] = maxx;
conInfo[conIdx][8] = miny;
conInfo[conIdx][9] = maxx;
conInfo[conIdx][10] = maxy;
}
}
}
}Two-pass法
由于业务环境为纯c,写Two-pass较为麻烦而且效率并不比种子填充高,因此这里只是贴了网上的代码。
1.生成等价对
要找一张二维图像中的连通域,很容易想到可以一行一行先把子区域找出来,然后再拼合成一个完整的连通域,因为从每一行找连通域是一件很简单的事。这个过程中需要记录每一个子区域,为了满足定位要求,并且节省内存,我们需要记录子区域所在的行号、区域开始和结束的位置以及子区域的总数。需要注意的就是子区域开始位置和结束位置在行首和行末的情况要单独拿出来考虑。
代码实现
// 查找每一行的子区域
// numberOfArea:子区域总数 stArea:子区域开始位置 enArea:子区域结束位置 rowArea:子区域所在行号
void searchArea(const Mat src, int &numberOfArea, vector<int> &stArea, vector<int> &enArea, vector<int> &rowArea)
{
for (int row = 0; row < src.rows; row++)
{
// 行指针
const uchar *rowData = src.ptr<uchar>(row);
// 判断行首是否是子区域的开始点
if (rowData[0] == 255){
numberOfArea++;
stArea.push_back(0);
}
for (int col = 1; col < src.cols; col++)
{
// 子区域开始位置的判断:前像素为背景,当前像素是前景
if (rowData[col - 1] == 0 && rowData[col] == 255)
{
numberOfArea++;
stArea.push_back(col);
// 子区域结束位置的判断:前像素是前景,当前像素是背景
}else if (rowData[col - 1] == 255 && rowData[col] == 0)
{
// 更新结束位置vector、行号vector
enArea.push_back(col - 1);
rowArea.push_back(row);
}
}
// 结束位置在行末
if (rowData[src.cols - 1] == 255)
{
enArea.push_back(src.cols - 1);
rowArea.push_back(row);
}
}
}
另外一个比较棘手的问题,如何给这些子区域标号,使得同一个连通域有相同的标签值。我们给单独每一行的子区域标号区分是很容易的事, 关键是处理相邻行间的子区域关系(怎么判别两个子区域是连通的)。
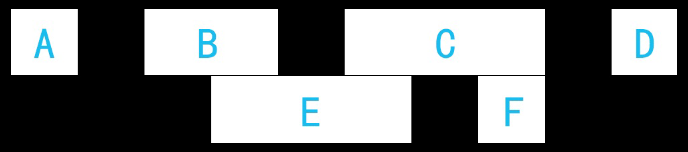
主要思路:以四连通为例,在上图我们可以看出BE是属于同一个连通域,判断的依据是E的开始位置小于B的结束位置,并且E的结束地址大于B的开始地址;同理可以判断出EC属于同一个连通域,CF属于同一个连通域,因此可以推知BECF都属于同一个连通域。
迭代策略:寻找E的相连区域时,对前一行的ABCD进行迭代,找到相连的有B和C,而D的开始地址已经大于了E的结束地址,此时就可以提前break掉,避免不必要的迭代操作;接下来迭代F的时候,由于有E留下来的基础,因此对上一行的迭代可以直接从C开始。另外,当前行之前的一行如果不存在子区域的话,那么当前行的所有子区域都可以直接赋新的标签,而不需要迭代上一行。
标签策略:以上图为例,遍历第一行,A、B、C、D会分别得到标签1、2、3、4。到了第二行,检测到E与B相连,之前E的标签还是初始值0,因此给E赋上B的标签2;之后再次检测到C和E相连,由于E已经有了标签2,而C的标签为3,则保持E和C标签不变,将(2,3)作为等价对进行保存。同理,检测到F和C相连,且F标签还是初始值0,则为F标上3。如此对所有的子区域进行标号,最终可以得到一个等价对的列表。
下面的代码实现了上述的过程。子区域用一维vector保存,没办法直接定位到某一行号的子区域,因此需要用curRow来记录当前的行,用firstAreaPrev记录前一行的第一个子区域在vector中的位置,用lastAreaPrev记录前一行的最后一个子区域在vector中的位置。在换行的时候,就去更新刚刚说的3个变量,其中firstAreaPrev的更新依赖于当前行的第一个子区域位置,所以还得用firstAreaCur记录当前行的第一个子区域。
// 初步标签,获取等价对
// labelOfArea:子区域标签值, equalLabels:等价标签对 offset:0为四连通,1为8连通
void markArea(int numberOfArea, vector<int> stArea, vector<int> enArea, vector<int> rowArea, vector<int> &labelOfArea, vector<pair<int, int>> &equalLabels, int offset)
{
int label = 1;
// 当前所在行
int curRow = 0;
// 当前行的第一个子区域位置索引
int firstAreaCur = 0;
// 前一行的第一个子区域位置索引
int firstAreaPrev = 0;
// 前一行的最后一个子区域位置索引
int lastAreaPrev = 0;
// 初始化标签都为0
labelOfArea.assign(numberOfArea, 0);
// 遍历所有子区域并标记
for (int i = 0; i < numberOfArea; i++)
{
// 行切换时更新状态变量
if (curRow != rowArea[i])
{
curRow = rowArea[i];
firstAreaPrev = firstAreaCur;
lastAreaPrev = i - 1;
firstAreaCur = i;
}
// 相邻行不存在子区域
if (curRow != rowArea[firstAreaPrev] + 1)
{
labelOfArea[i] = label++;
continue;
}
// 对前一行进行迭代
for (int j = firstAreaPrev; j <= lastAreaPrev; j++)
{
// 判断是否相连
if (stArea[i] <= enArea[j] + offset && enArea[i] >= stArea[j] - offset)
{
// 之前没有标记过
if (labelOfArea[i] == 0)
labelOfArea[i] = labelOfArea[j];
// 之前已经被标记,保存等价对
else if (labelOfArea[i] != labelOfArea[j])
equalLabels.push_back(make_pair(labelOfArea[i], labelOfArea[j]));
}else if (enArea[i] < stArea[j] - offset)
{
// 为当前行下一个子区域缩小上一行的迭代范围
firstAreaPrev = max(firstAreaPrev, j - 1);
break;
}
}
// 与上一行不存在相连
if (labelOfArea[i] == 0)
{
labelOfArea[i] = label++;
}
}
}2.DFS Two-pass算法
建立一个Bool型等价对矩阵,用作深搜环境。具体做法是先获取最大的标签值maxLabel,然后生成一个maxLabel∗maxLabel大小的二维矩阵,初始值为false;对于例如(1,3)这样的等价对,在矩阵的(0,2)和(2,0)处赋值true——要注意索引和标签值是相差1的。就这样把所有等价对都反映到矩阵上。
深搜的目的在于建立一个标签的重映射。例如4、5、8是等价的标签,都重映射到标签2。最后重映射的效果就是标签最小为1,且依次递增,没有缺失和等价。深搜在这里就是优先地寻找一列等价的标签,例如一口气把4、5、8都找出来,然后给他们映射到标签2。程序也维护了一个队列,当标签在矩阵上值为true,而且没有被映射过,就加入到队列。
当然不一定要建立一个二维等价矩阵,一般情况,等价对数量要比maxLabel来的小,所以也可以直接对等价对列表进行深搜,但无论采用怎样的深搜,其等价对处理的性能都不可能提高很多。
代码实现
// 等价对处理,标签重映射
void replaceEqualMark(vector<int> &labelOfArea, vector<pair<int, int>> equalLabels)
{
int maxLabel = *max_element(labelOfArea.begin(), labelOfArea.end());
// 等价标签矩阵,值为true表示这两个标签等价
vector<vector<bool>> eqTab(maxLabel, vector<bool>(maxLabel, false));
// 将等价对信息转移到矩阵上
vector<pair<int, int>>::iterator labPair;
for (labPair = equalLabels.begin(); labPair != equalLabels.end(); labPair++)
{
eqTab[labPair->first -1][labPair->second -1] = true;
eqTab[labPair->second -1][labPair->first -1] = true;
}
// 标签映射
vector<int> labelMap(maxLabel + 1, 0);
// 等价标签队列
vector<int> tempList;
// 当前使用的标签
int curLabel = 1;
for (int i = 1; i <= maxLabel; i++)
{
// 如果该标签已被映射,直接跳过
if (labelMap[i] != 0)
{
continue;
}
labelMap[i] = curLabel;
tempList.push_back(i);
for (int j = 0; j < tempList.size(); j++)
{
// 在所有标签中寻找与当前标签等价的标签
for (int k = 1; k <= maxLabel; k++)
{
// 等价且未访问
if (eqTab[tempList[j] - 1][k - 1] && labelMap[k] == 0)
{
labelMap[k] = curLabel;
tempList.push_back(k);
}
}
}
curLabel++;
tempList.clear();
}
// 根据映射修改标签
vector<int>::iterator label;
for (label = labelOfArea.begin(); label != labelOfArea.end(); label++)
{
*label = labelMap[*label];
}
return;
}
2.并查集 Two-pass算法
等价对,实质是一种关系分类,因而联想到并查集。并查集方法在这个问题上显得非常合适,首先将等价对进行综合就是合并操作,标签重映射就是查询操作(并查集可以看做一种多对一映射)。这里定义成了类。
代码实现
#include<opencv2/opencv.hpp>
#include<iostream>
using namespace std;
using namespace cv;
class AreaMark
{
public:
AreaMark(const Mat src,int offset);
int getMarkedArea(vector<vector<int>> &area);
void getMarkedImage(Mat &dst);
private:
Mat src;
int offset;
int numberOfArea=0;
vector<int> labelMap;
vector<int> labelRank;
vector<int> stArea;
vector<int> enArea;
vector<int> rowArea;
vector<int> labelOfArea;
vector<pair<int, int>> equalLabels;
void markArea();
void searchArea();
void setInit(int n);
int findRoot(int label);
void unite(int labelA, int labelB);
void replaceEqualMark();
};
// 构造函数
// imageInput:输入待标记二值图像 offsetInput:0为四连通,1为八连通
AreaMark::AreaMark(Mat imageInput,int offsetInput)
{
src = imageInput;
offset = offsetInput;
}
// 使用可区分的颜色标记连通域
void AreaMark::getMarkedImage(Mat &dst)
{
Mat img(src.rows, src.cols, CV_8UC3, CV_RGB(0, 0, 0));
cvtColor(img, dst, CV_RGB2HSV);
int maxLabel = *max_element(labelOfArea.begin(), labelOfArea.end());
vector<uchar> hue;
for (int i = 1; i<= maxLabel; i++)
{
// HSV color-mode
hue.push_back(uchar(180.0 * (i - 1) / (maxLabel + 1)));
}
for (int i = 0; i < numberOfArea; i++)
{
for (int j = stArea[i]; j <= enArea[i]; j++)
{
dst.at<Vec3b>(rowArea[i], j)[0] = hue[labelOfArea[i]];
dst.at<Vec3b>(rowArea[i], j)[1] = 255;
dst.at<Vec3b>(rowArea[i], j)[2] = 255;
}
}
cvtColor(dst, dst, CV_HSV2BGR);
}
// 获取标记过的各行子区域
int AreaMark::getMarkedArea(vector<vector<int>> &area)
{
searchArea();
markArea();
replaceEqualMark();
area.push_back(rowArea);
area.push_back(stArea);
area.push_back(enArea);
area.push_back(labelOfArea);
return numberOfArea;
}
// 查找每一行的子区域
// numberOfArea:子区域总数 stArea:子区域开始位置 enArea:子区域结束位置 rowArea:子区域所在行号
void AreaMark::searchArea()
{
for (int row = 0; row < src.rows; row++)
{
// 行指针
const uchar *rowData = src.ptr<uchar>(row);
// 判断行首是否是子区域的开始点
if (rowData[0] == 255){
numberOfArea++;
stArea.push_back(0);
}
for (int col = 1; col < src.cols; col++)
{
// 子区域开始位置的判断:前像素为背景,当前像素是前景
if (rowData[col - 1] == 0 && rowData[col] == 255)
{
numberOfArea++;
stArea.push_back(col);
// 子区域结束位置的判断:前像素是前景,当前像素是背景
}else if (rowData[col - 1] == 255 && rowData[col] == 0)
{
// 更新结束位置vector、行号vector
enArea.push_back(col - 1);
rowArea.push_back(row);
}
}
// 结束位置在行末
if (rowData[src.cols - 1] == 255)
{
enArea.push_back(src.cols - 1);
rowArea.push_back(row);
}
}
}
void AreaMark::markArea()
{
int label = 1;
// 当前所在行
int curRow = 0;
// 当前行的第一个子区域位置索引
int firstAreaCur = 0;
// 前一行的第一个子区域位置索引
int firstAreaPrev = 0;
// 前一行的最后一个子区域位置索引
int lastAreaPrev = 0;
// 初始化标签都为0
labelOfArea.assign(numberOfArea, 0);
// 遍历所有子区域并标记
for (int i = 0; i < numberOfArea; i++)
{
// 行切换时更新状态变量
if (curRow != rowArea[i])
{
curRow = rowArea[i];
firstAreaPrev = firstAreaCur;
lastAreaPrev = i - 1;
firstAreaCur = i;
}
// 相邻行不存在子区域
if (curRow != rowArea[firstAreaPrev] + 1)
{
labelOfArea[i] = label++;
continue;
}
// 对前一行进行迭代
for (int j = firstAreaPrev; j <= lastAreaPrev; j++)
{
// 判断是否相连
if (stArea[i] <= enArea[j] + offset && enArea[i] >= stArea[j] - offset)
{
// 之前没有标记过
if (labelOfArea[i] == 0)
labelOfArea[i] = labelOfArea[j];
// 之前已经被标记,保存等价对
else if (labelOfArea[i] != labelOfArea[j])
equalLabels.push_back(make_pair(labelOfArea[i], labelOfArea[j]));
}else if (enArea[i] < stArea[j] - offset)
{
// 为当前行下一个子区域缩小上一行的迭代范围
firstAreaPrev = max(firstAreaPrev, j - 1);
break;
}
}
// 与上一行不存在相连
if (labelOfArea[i] == 0)
{
labelOfArea[i] = label++;
}
}
}
//集合初始化
void AreaMark::setInit(int n)
{
for (int i = 0; i <= n; i++)
{
labelMap.push_back(i);
labelRank.push_back(0);
}
}
//查找树根
int AreaMark::findRoot(int label)
{
if (labelMap[label] == label)
{
return label;
}
else
{
// path compression
return labelMap[label] = findRoot(labelMap[label]);
}
}
// 合并集合
void AreaMark::unite(int labelA, int labelB)
{
labelA = findRoot(labelA);
labelB = findRoot(labelB);
if (labelA == labelB)
{
return;
}
// rank optimization:tree with high rank merge tree with low rank
if (labelRank[labelA] < labelRank[labelB])
{
labelMap[labelA] = labelB;
}
else
{
labelMap[labelB] = labelA;
if (labelRank[labelA] == labelRank[labelB])
{
labelRank[labelA]++;
}
}
}
// 等价对处理,标签重映射
void AreaMark::replaceEqualMark()
{
int maxLabel = *max_element(labelOfArea.begin(), labelOfArea.end());
setInit(maxLabel);
// 合并等价对,标签初映射
vector<pair<int, int>>::iterator labPair;
for (labPair = equalLabels.begin(); labPair != equalLabels.end(); labPair++)
{
unite(labPair->first, labPair->second);
}
// 标签重映射,填补缺失标签
int newLabel=0;
vector<int> labelReMap(maxLabel + 1, 0);
vector<int>::iterator old;
for (old = labelMap.begin(); old != labelMap.end(); old++)
{
if (labelReMap[findRoot(*old)] == 0)
{
labelReMap[findRoot(*old)] = newLabel++;
}
}
// 根据重映射结果修改标签
vector<int>::iterator label;
for (label = labelOfArea.begin(); label != labelOfArea.end(); label++)
{
*label = labelReMap[findRoot(*label)];
}
}
int main()
{
Mat img = imread("img/qrcode.jpg", IMREAD_GRAYSCALE);
threshold(img, img, 0, 255, THRESH_OTSU);
AreaMark marker(img, 0);
vector<vector<int>> area;
int amount;
// 1s for 1000 times
amount = marker.getMarkedArea(area);
Mat dst;
marker.getMarkedImage(dst);
imshow("img", img);
imshow("dst", dst);
waitKey(0);
}霍夫变换
直线检测
标准霍夫变换
首先该检测算法的输入图像只能是边缘二值图像。
1.一条直线在图像二维空间可由两个变量表示:
· 在笛卡尔坐标系:y = kx + b,可由k、b表示。
· 在极坐标系:ρ = xcosθ + ysinθ,可由ρ、θ表示
2.对于点(x0,y0),可将经过这个点的一簇直线定义为ρ = x0cosθ + y0sinθ
2.很自然的,对于两个点,满足同一对(ρ,θ)时,这两个点处于同一直线上
3.于是,当有更多个点满足同一对(ρ,θ)时,该对表示的直线由更多的点组成.。一般可以通过设置直线上点的阈值来定义多少个点组成的(ρ,θ)能被认为是一条直线。
4.霍夫变换追踪图像中每个点对应的所有(ρ,θ)并记录数量,若超过了阈值, 那么可以认为这个交点所代表的参数对在原图像中为一条直线。
代码实现
对于图像的每个像素点,遍历 [0, PI] 共180个θ值,得到相应的ρ,并对每一组(ρ,θ)记录值+1(计分板)。
遍历计分板,找出分数大于设定阈值的(ρ,θ)对,即为检测到的直线参数,再将其还原为数学概念上的直线即可。
累计概率霍夫变换(常用)
它是对标准霍夫变换的改进。在一定的范围内进行霍夫变换,计算单独线段的方向以及范围,从而减少计算量,缩短计算时间。之所以称PPHT为“概率”的,是因为并不将累加器平面内的所有可能的点累加,而只是累加其中的一部分,该想法是如果峰值如果足够高,只用一小部分时间去寻找它就够了。这样猜想的话,可以实质性地减少计算时间。
代码实现
1.随机获取边缘图像上的前景点,映射到极坐标系画曲线;
2.当极坐标系里面有交点达到最小投票数,将该点对应x-y坐标系的直线L找出来;
3.搜索边缘图像上前景点,在直线L上的点(且点与点之间距离小于maxLineGap的)连成线段,然后这些点全部删除,并且记录该线段的参数(起始点和终止点),当然线段长度要满足最小长度;
4.重复1. 2. 3.。
opencv函数
HoughLinesP(InputArray image, OutputArray lines, double rho, double theta, int threshold,
double minLineLength = 0, double maxLineGap = 0)
池化
池化的作用:减少特征图大小,也就是可以减少计算量和所需显存。
平均池化(mean-pooling)
即对邻域内特征点只求平均
优缺点:能很好的保留背景,但容易使得图片变模糊
正向传播:邻域内取平均
反向传播:特征值根据领域大小被平均,然后传给每个索引位置
最大池化(max-pooling)
即对邻域内特征点取最大
优缺点:能很好的保留纹理特征,一般现在都用最大而很少用平均
正向传播:取邻域内最大,并记住最大值的索引位置,以方便反向传播
反向传播:将特征值填充到正向传播中,值最大的索引位置,其他位置补0
随机池化(stochastic-pooling)
只需对邻域中的元素按照其概率值大小随机选择,即元素值大的被选中的概率也大。而不像max-pooling那样,永远只取那个最大值元素。
在区域内,将左图的数值进行归一化处理,即 1/(1+2+3+4)=0.1;2/10=0.2;3/10=0.3;4/10=0.4
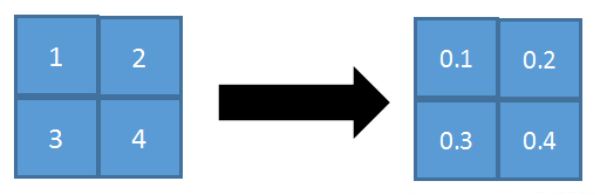
正向传播:对矩阵区域求加权平均即可,比如上面图中,池化输出值为:1 * 0.1+2 * 0.2+3 * 0.3+4 * 0.4=3。
反向传播:只需保留前向传播已经记录被选中节点的位置的值,其它值都为0,这和max-pooling的反向传播非常类似。
优点:方法简单,泛化能力更强(带有随机性)
颜色
亮度与对比度
基础线性变化
在查询opencv的亮度与对比度变化算法时,大多是博客都采用的最基础的线性变换:
out = in * α + β
其中 α 为对比度的变化,β 为亮度变化。
亮度(β):像素点的值就是0~255,0为黑表示最暗,255为白表示最亮。因此调节亮度就是简单的对像素值进行增减即可,即 β ∈ (-100,-100) 。
对比度(α):这里就存在问题了,线性变化的对比度调节非常不明显,在视觉上依旧呈现的是亮度的变化,在进行代码编写的时候一直达不到Photoshop里面的对比度调节效果。
改进
通过查阅资料不难发现,对比度的调节原理如下:
对比度反应了图片上亮区域和暗区域的层次感。而反应到图像编辑上,调整对比度就是在保证平均亮度不变的情况下,扩大或缩小亮的点和暗的点的差异。既然是要保证平均亮度不变,所以对每个点的调整比例必须作用在该值和平均亮度的差值之上,这样才能够保证计算后的平均亮度不变。
因此很容易得出对比度变化的调整公式如下:
out = (in - average) * α + in
其中average为图像的平均亮度,α ∈ (-1,1) 。
但是实际处理中,并没有太多的必要去计算一张图的平均亮度:一来耗时间,二来在平均亮度上的精确度并不会给图像的处理带来太多的好处。因此一般假设一张图的平均亮度为127,即一半亮度,而一张正常拍照拍出来的图平均亮度应该是在[100,150]。在视觉上基本没有任何区别。
于是可得最终的亮度对比度调节公式:
out = (in - average) * α + in + β
达到了和Photoshop相同的效果。
通道混合
也就是调整某一个通道中的颜色成分,可以理解为调整图片某一颜色区域的颜色。
对于选中通道的每一个像素值,进行如下变换:
out = red * r + green * g + blue * b + constant * 255
其中,red、green、blue ∈ (-2, 2) ,**constant ∈ (-1, 1)**,r、g、b为每一个像素点的三个通道的值。
gamma变换(校正)
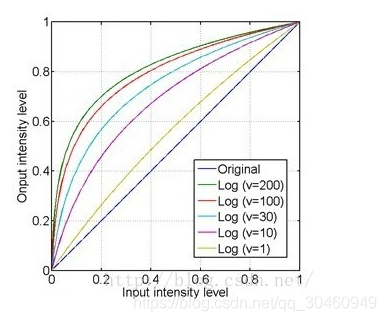
Gamma校正是一种非常重要的非线性变换。对输入图像的灰度值进行指数变换,进而校正亮度偏差,通常应用于扩展暗调的细节。gamma校正可使得图像看起来更符合人眼的特性。
但其实Gamma校正不仅会改变亮度,还会改变彩色图像中rgb的比率。
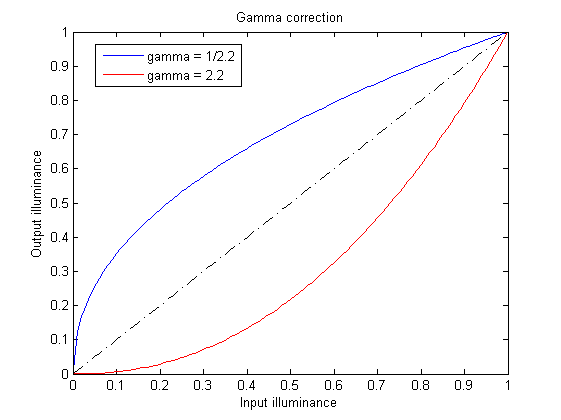
当Gamma校正的值大于1时,图像的高光部分被压缩而暗调部分被扩展,图像整体变暗;
当Gamma校正的值小于1时,图像的高光部分被压缩而暗调部分被压缩,图像整体变亮。
gamma校正的作用:
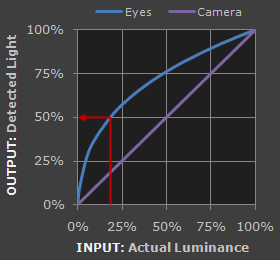
1.人眼对外界光源的感光值与输入光强不是呈线性关系的,而是呈指数型关系的。在低照度下,人眼更容易分辨出亮度的变化,随着照度的增加,人眼不易分辨出亮度的变化。而摄像机感光与输入光强呈线性关系。
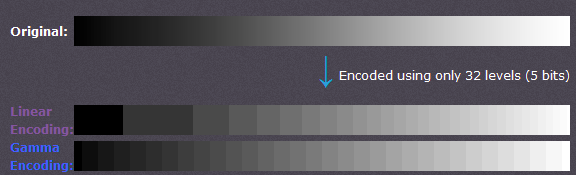
2.为能更有效的保存图像亮度信息。未经Gamma变换和经过Gamma变换保存图像信息如下所示:可以观察到,未经Gamma变换的情况下,低灰度时,有较大范围的灰度值被保存成同一个值,造成信息丢失;同时高灰度值时,很多比较接近的灰度值却被保存成不同的值,造成空间浪费。经过Gamma变换后,改善了存储的有效性和效率。
Gamma校正主要应用在图像增强、目标检测以及图像分析等领域。表达式如下:
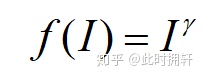
代码实现
unsigned char newPixel = static_cast<unsigned char>(pow(pixel / 255.0, gamma) * 255);对数变换
由于对数曲线在像素值较低的区域斜率大,在像素值较高的区域斜率较小,所以图像经过对数变换后,较暗区域的对比度将有所提升,所以就可以增强图像的暗部细节。
对数变换可以将图像的低灰度值部分扩展,显示出低灰度部分更多的细节,将其高灰度值部分压缩,减少高灰度值部分的细节,从而达到强调图像低灰度部分的目的。表达式如下:

图像的归一化
所谓归一化,就是把需要处理的数据限制在你需要的一定范围内。
首先归一化是为了后面数据处理的方便,其次是保证程序运行时收敛加快。归一化的具体作用是归纳统一样本的统计分布性。归一化在0-1之间是统计的概率分布,归一化在某个区间上是统计的坐标分布。
而图像的归一化用的最多的就是归一化到(min,max)范围内:
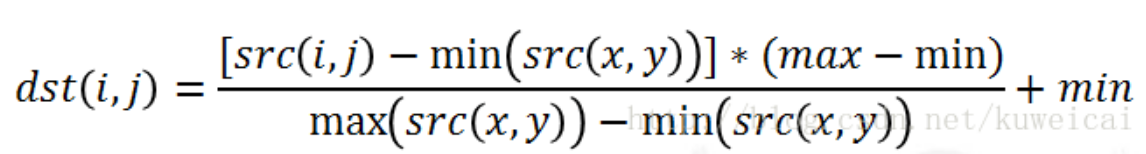
代码实现
首先迭代整个图的像素点,获取max( src( x,y ) )和min像素点。
然后再次迭代整张图的像素点,将低于min的设置为min,高于max 的设置为max,在(min,max)之间的通过上式计算即可。
图像的均衡化
直方图均衡化,是对图像像素值进行非线性拉伸,使得一定范围内像素值的数量的大致相同。这样原来直方图中的封顶部分对比度得到了增强,而两侧波谷的对比度降低,输出的直方图是一个较为平坦的分段直方图。如下图所示:
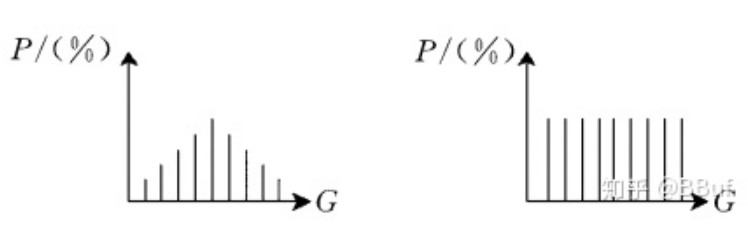
通过这种方法可以按照需要对图像的亮度进行调整,并且,这种方法是可逆的,也就是说知道了均衡化函数,也可以恢复原始的直方图。
为什么要选用累积分布函数?
均衡化过程中,必须要保证两个条件:①像素无论怎么映射,一定要保证原来的大小关系不变,较亮的区域,依旧是较亮的,较暗依旧暗,只是对比度增大,绝对不能明暗颠倒;②如果是八位图像,那么像素映射函数的值域应在0和255之间的,不能越界。综合以上两个条件,累积分布函数是个好的选择,因为累积分布函数是单调增函数(控制大小关系),并且值域是0到1(控制越界问题),所以直方图均衡化中使用的是累积分布函数。
为什么使用累积分布函数处理后像素值会均匀分布?
比较概率分布函数和累积分布函数,前者的二维图像是参差不齐的,后者是单调递增的。直方图均衡化过程中,映射方法是:
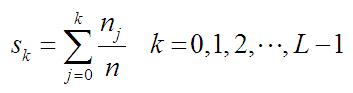
其中,n是图像中像素点的总数,nk是当前灰度级的像素个数,L是图像中可能的灰度级总数。
于是对于像素值为k的点,只需要计算: 像素为0~k的点的数量 / 像素点总数,就可以得到直方图中的纵坐标(比例)。再乘以255,即为该点经过均衡化后的像素点。
RGB转灰度
一、基础
对于彩色转灰度,有一个很著名的心理学公式:
Gray = R * 0.299 + G * 0.587 + B * 0.114
二、整数算法
而实际应用时,希望避免低速的浮点运算,所以需要整数算法。
注意到系数都是3位精度的没有,我们可以将它们缩放1000倍来实现整数运算算法:
Gray = (R * 299 + G * 587 + B * 114 + 500) / 1000
RGB一般是8位精度,现在缩放1000倍,所以上面的运算是32位整型的运算。注意后面那个除法是整数除法,所以需要加上500来实现四舍五入。
三、整数移位算法
上面的整数算法已经很快了,但是有一点仍制约速度,就是最后的那个除法。移位比除法快多了,所以可以将系数缩放成 2的整数幂。
习惯上使用16位精度,2的16次幂是65536,所以这样计算系数:
0.299 * 65536 = 19595.264 ≈ 19595
0.587 * 65536 + (0.264) = 38469.632 + 0.264 = 38469.896 ≈ 38469
0.114 * 65536 + (0.896) = 7471.104 + 0.896 = 7472
这所使用的舍入方式不是四舍五入。四舍五入会有较大的误差,应该将以前的计算结果的误差一起计算进去,舍入方式是去尾法,表达式是:
Gray = (R * 19595 + G * 38469 + B * 7472) >> 16
同理,2至20位精度的系数:
Gray = (R * 1 + G * 2 + B * 1) >> 2
Gray = (R * 2 + G * 5 + B * 1) >> 3
Gray = (R * 4 + G * 10 + B * 2) >> 4
Gray = (R * 9 + G * 19 + B * 4) >> 5
Gray = (R * 19 + G * 37 + B * 8) >> 6
Gray = (R * 38 + G * 75 + B * 15) >> 7
Gray = (R * 76 + G * 150 + B * 30) >> 8
Gray = (R * 153 + G * 300 + B * 59) >> 9
Gray = (R * 306 + G * 601 + B * 117) >> 10
Gray = (R * 612 + G * 1202 + B * 234) >> 11
Gray = (R * 1224 + G * 2405 + B * 467) >> 12
Gray = (R * 2449 + G * 4809 + B * 934) >> 13
Gray = (R * 4898 + G * 9618 + B * 1868) >> 14
Gray = (R * 9797 + G * 19235 + B * 3736) >> 15
Gray = (R * 19595 + G * 38469 + B * 7472) >> 16
Gray = (R * 39190 + G * 76939 + B * 14943) >> 17
Gray = (R * 78381 + G * 153878 + B * 29885) >> 18
Gray = (R * 156762 + G * 307757 + B * 59769) >> 19
Gray = (R * 313524 + G * 615514 + B * 119538) >> 20
这些精度实际上是一样的:3与4、7与8、10与11、13与14、19与20
所以16位运算下最好的计算公式是使用7位精度,比先前那个系数缩放100倍的精度高,而且速度快
Gray = (R * 38 + G * 75 + B * 15) >> 7
灰度转伪彩色
本质就是将灰度值根据一定的比例关系转化为RGB三通道值。
人类能够观察到的光的波长范围是有限的,并且人类视觉有一个特点,只能分辨出二十几种灰度,也就是说即使采集到的灰度图像分辨率超级高,有上百个灰度级,但是很遗憾,人们只能看出二十几个,也就是说信息损失了五十倍。但人类视觉对彩色的分辨能力相当强,能够分辨出几千种色度。
以下为opencv中ColorMap提供的21种不同伪彩色:


根据源码中获得的数组对每个像素进行转换即可。
RGB模型
图像处理中,最常用的颜色空间是RGB模型,常用于颜色显示和图像处理,三维坐标的模型形式。

原点到白色顶点的中轴线是灰度线,r、g、b三分量相等,强度可以由三分量的向量表示。
用RGB来理解色彩、深浅、明暗变化如下:
色彩变化: 三个坐标轴RGB最大分量顶点与黄紫青YMC色顶点的连线
深浅变化:RGB顶点和CMY顶点到原点和白色顶点的中轴线的距离
明暗变化:中轴线的点的位置,到原点,就偏暗,到白色顶点就偏亮
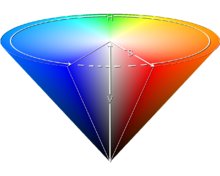
HSV色域
这是针对用户观感的一种颜色模型,侧重于色彩表示,什么颜色、深浅如何、明暗如何。
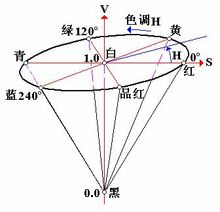
色调H
用角度度量,取值范围为0°~360°,从红色开始按逆时针方向计算,红色为0°,绿色为120°,蓝色为240°。它们的补色是:黄色为60°,青色为180°,品红为300°;
饱和度S
饱和度S表示颜色接近光谱色的程度。一种颜色,可以看成是某种光谱色与白色混合的结果。其中光谱色所占的比例愈大,颜色接近光谱色的程度就愈高,颜色的饱和度也就愈高。饱和度高,颜色则深而艳。光谱色的白光成分为0,饱和度达到最高。通常取值范围为0%~100%,值越大,颜色越饱和。
明度V
明度表示颜色明亮的程度,对于光源色,明度值与发光体的光亮度有关;对于物体色,此值和物体的透射比或反射比有关。通常取值范围为0%(黑)到100%(白)。
H是色彩
S是深浅, S = 0时,只有灰度
V是明暗,表示色彩的明亮程度
把RGB三维坐标的中轴线立起来,并扁化,就能形成HSV的锥形模型了。
RGB到HSV转化模型
首先要将图像的R、G、B三个通道的分量归一化到0 ~ 1之间。
我们设max为该像素点的RGB中的最大值,min为最小值,有如下公式:
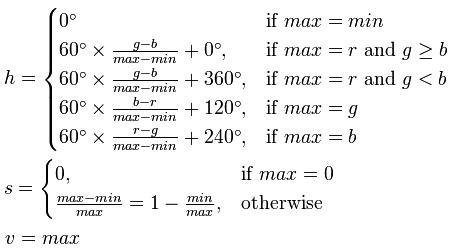
float max = 0,min = 0;
max = retmax(R,G,B); // 计算三者的最大值
min = retmin(R,G,B);
v = max;
if(max == 0)
s = 0;
else
s = 1 - (min / max);
if(max == min)
h = 0;
else if(max == R && G >= B)
h = 60 * ((G - B) / (max - min));
else if(max == R && G < B)
h = 60 * ((G - B) / (max - min)) + 360;
else if(max == G)
h = 60 * ((B - R) / (max - min)) + 120;
else if(max == B)
h = 60 * ((R - G) / (max - min)) + 240;HSV到RGB转化模型

float C = 0,X = 0,Y = 0,Z = 0;
int i = 0;
float H = h / 1.0;
float S = s / 100.0;
float V = v / 100.0;
if(S == 0)
R = G = B = V;
else
{
H = H / 60;
i = (int)H;
C = H - i;
X = V * (1 - S);
Y = V * (1 - S * C);
Z = V * (1 - S * (1 - C));
switch(i){
case 0 : R = V; G = Z; B = X; break;
case 1 : R = Y; G = V; B = X; break;
case 2 : R = X; G = V; B = Z; break;
case 3 : R = X; G = Y; B = V; break;
case 4 : R = Z; G = X; B = V; break;
case 5 : R = V; G = X; B = Y; break;
}
}HSI色域
与HSV色域表达的意义类似,区别在于取值的方式,基于I和V。
二者都是表示明度,V取值为R、G、B中的最大值,而I取值为R、G、B的均值。
RGB到HSI转化模型

HSI到RGB转化模型

HSL色域
是工业界的另一种色彩模型标准。
HSL 和 HSV二者都把颜色描述在圆柱体内的点,这个圆柱的中心轴取值为自底部的黑色到顶部的白色而在它们中间是的灰色,绕这个轴的角度对应于“色相”,到这个轴的距离对应于“饱和度”,而沿着这个轴的距离对应于“亮度”,“色调”或“明度”。
这两种表示在目的上类似,但在方法上有区别。二者在数学上都是圆柱,但 HSV(色相,饱和度,明度)在概念上可以被认为是颜色的倒圆锥体(黑点在下顶点,白色在上底面圆心),HSL在概念上表示了一个双圆锥体和圆球体(白色在上顶点,黑色在下顶点,最大横切面的圆心是半程灰色)。注意尽管在HSL 和HSV 中“色相”指称相同的性质,它们的“饱和度”的定义是明显不同的。
在 HSL 中,饱和度分量总是从完全饱和色变化到等价的灰色(在 HSV 中,在极大值 V 的时候,饱和度从全饱和色变化到白色,这可以被认为是反直觉的)。
在 HSL 中,亮度跨越从黑色过选择的色相到白色的完整范围(在 HSV 中,V 分量只走一半行程,从黑到选择的色相)。
RGB到HSL转化模型
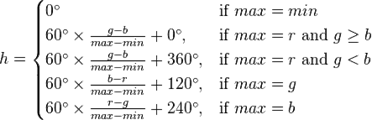
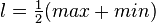
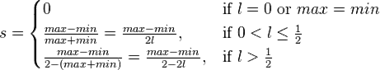
HSL到RGB转化模型

差影法
原理上来说就是两幅图像作差对应的像素点之间作差。
常用于判断两幅角度相同的相似图像之间的差别。
可以通过对差值乘以一个倍数,实现放大差别的效果。
是否对差值使用绝对值计算,对作差的结果有一定影响。
二值化
普通二值化
遍历判断图像每个像素点的值,如果大于设定的阈值,则修改为255,如果小于,则修改为0。
大津法二值化
图像分割中阈值选取的最佳算法,计算简单,不受图像亮度和对比度的影响。它是按图像的灰度特性,将图像分成背景和前景两部分。因方差是灰度分布均匀性的一种度量,背景和前景之间的类间方差越大,说明构成图像的两部分的差别越大,当部分前景错分为背景或部分背景错分为前景都会导致两部分差别变小。因此,使类间方差最大的分割意味着错分概率最小。
优点:计算简单快速,不受图像亮度和对比度的影响。适用于大部分需要求图像全局阈值的场合。
缺点:对图像噪声敏感;只能针对单一目标分割;当目标和背景大小比例悬殊、类间方差函数可能呈现双峰或者多峰,这个时候效果不好。
实现原理
同样用到了最大类间方差的概念,参考下面双阈值三值化,不再多叙述。
注:
为了快速计算,可将类间方差计算公式:σ^2 = p1 * ( m1 - mg ) ^ 2 + p2 * ( m2 - mg ) ^ 2
简化为:σ^2 = p1 * p2 * ( m1 - m2 ) ^ 2
局部自适应二值化
核心就是对每个像素点,计算它指定大小邻域内的阈值,来作为这个像素点的二值化阈值。
邻域阈值的计算方法常用的有两种:均值和高斯加权和。
计算方法非常简单,在本文上述提到的均值滤波和高斯滤波的基础上,对计算出的每个像素点邻域内的均值或高斯加权和,减去一个指定的偏移量,就是该点的二值化阈值了。
双阈值三值化
首先获取图像像素的直方图,即像素值为0 - 255的点分别有几个,并分别计算它们占总像素点数的比例(即一个点为该像素值的概率,Pi(i=0 - 255))。
其次设定两个阈值k1和k2,将0 - 255分为三类(0 - k1,k1 - k2,k2 - 255),计算:
一个点被分为其中一类的概率,表现为该类像素范围内概率的和。
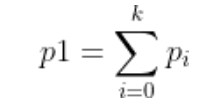
这三类各自的像素均值,表现为:
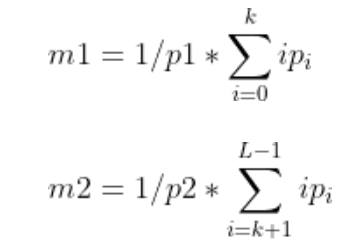
于是有:mg = p1 * m1 + p2 * m2 + p3 * m3,且 p1+p2+p3 = 1
可得类间方差:(更多或更少类均同理)
σ^2 = p1 * ( m1 - mg ) ^ 2 + p2 * ( m2 - mg ) ^ 2 + p3 * ( m3 - mg ) ^ 2
最终目的是为了获得当类间方差最大时的k1和k2
最后只需要判断每个像素点的值在这三类中的哪类,分别修改值为0,128,255即可。
因此代码实现为:
for (k1 = 1; k1 < 256; k1++){
for (k2 = 1; k2 < 256; k2++){
for (int i = 0; i < k1; i++){
p1 += Pi;
m1 += i * Pi;
}
for (int i = k1; i < k2; i++){
p2 += Pi;
m2 += i * Pi;
}
for (int i = k2; i < 256; i++){
p3 += Pi;
m3 += i * Pi;
}
mg = m1 + m2 + m3;
m1 /= p1;
m2 /= p2;
m3 /= p3;
// 类间方差
double sigma = p1 * pow(m1 - mg, 2) + p2 * pow(m2 - mg, 2) + p3 * pow(m3 - mg, 2);
if (max < sigma){
max = sigma;
thres1 = k1;
thres2 = k2;
}
}
}几何变换
图像的缩放
最近邻插值
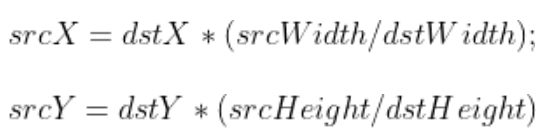
由于缩放比例(即srcWidth / dstWidth)基本上是浮点数值,而最后得到的图像坐标(srcX)是整数。因此需要对等式右边的值进行四舍五入的操作:
int srcX = static_cast<int>(dstX * (srcWidth / dstWidth) + 0.5f);
// 其中static_cast用于强制转换为int类型
// +0.5f是为了实现四舍五入而不是舍去小数点后的值这种方法在放大图像时容易导致图像的严重失真,根源在于当坐标是浮点数时直接四舍五入取最近的整数。
双线性插值
线性插值的解释
已知数据 (x0, y0) 与 (x1, y1),要计算 [x0, x1] 区间内某一位置 x 在直线上的y值。

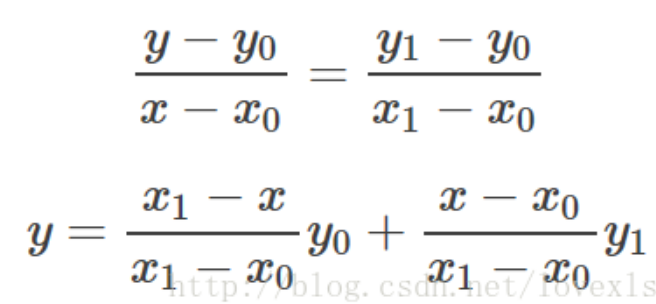
双线性插值是有两个变量的插值函数的线性插值扩展,其核心思想是在两个方向分别进行一次线性插值。如下图:
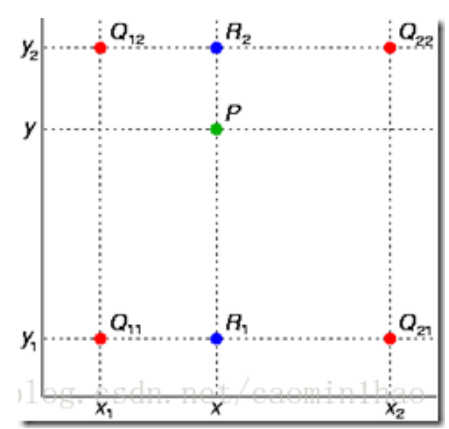
假如我们想得到未知函数 f 在点 P = (x, y) 的值,假设我们已知函数 f 在 Q11 = (x1, y1)、Q12 = (x1, y2), Q21 = (x2, y1) 以及 Q22 = (x2, y2) 四个点的值。最常见的情况,f就是一个像素点的像素值。首先在 x 方向进行线性插值,得到:
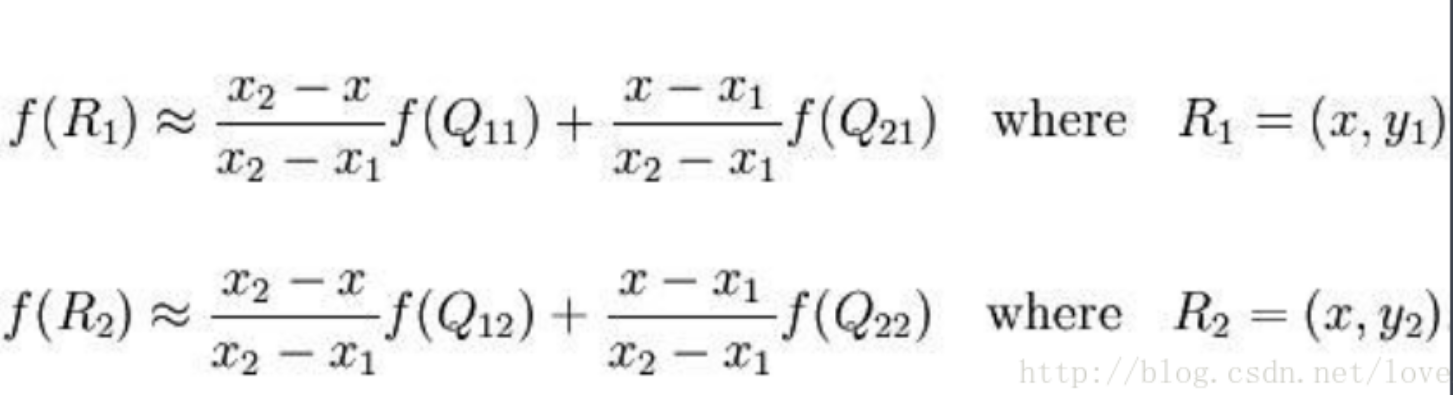
然后在上述基础上(R1和R2),在 y 方向进行线性插值,得到:
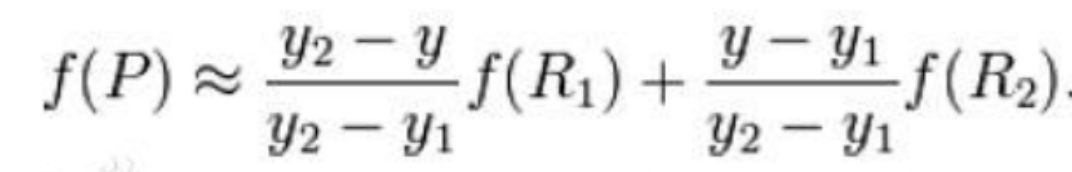
展开即为最终结果:
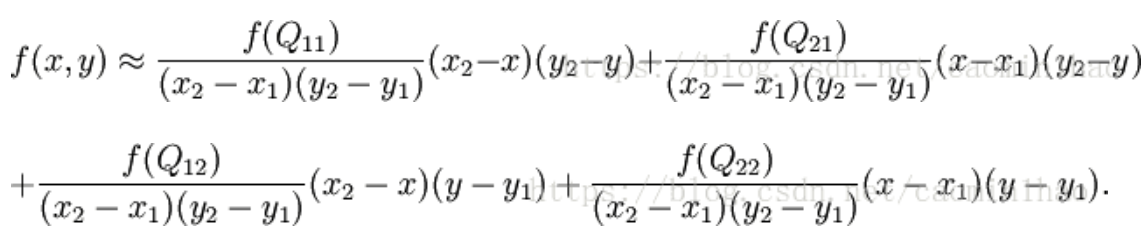
代码实现
由于图像双线性插值只会用相邻的4个点,因此上述公式的分母都是1。opencv中的源码如下,用了一些优化手段:
用整数计算代替float(下面代码中的 * 2048就是变11位小数为整数,最后有两个连乘,因此>>22位)
源图像和目标图像几何中心的对齐
SrcX=(dstX + 0.5) * (srcWidth/dstWidth) -0.5
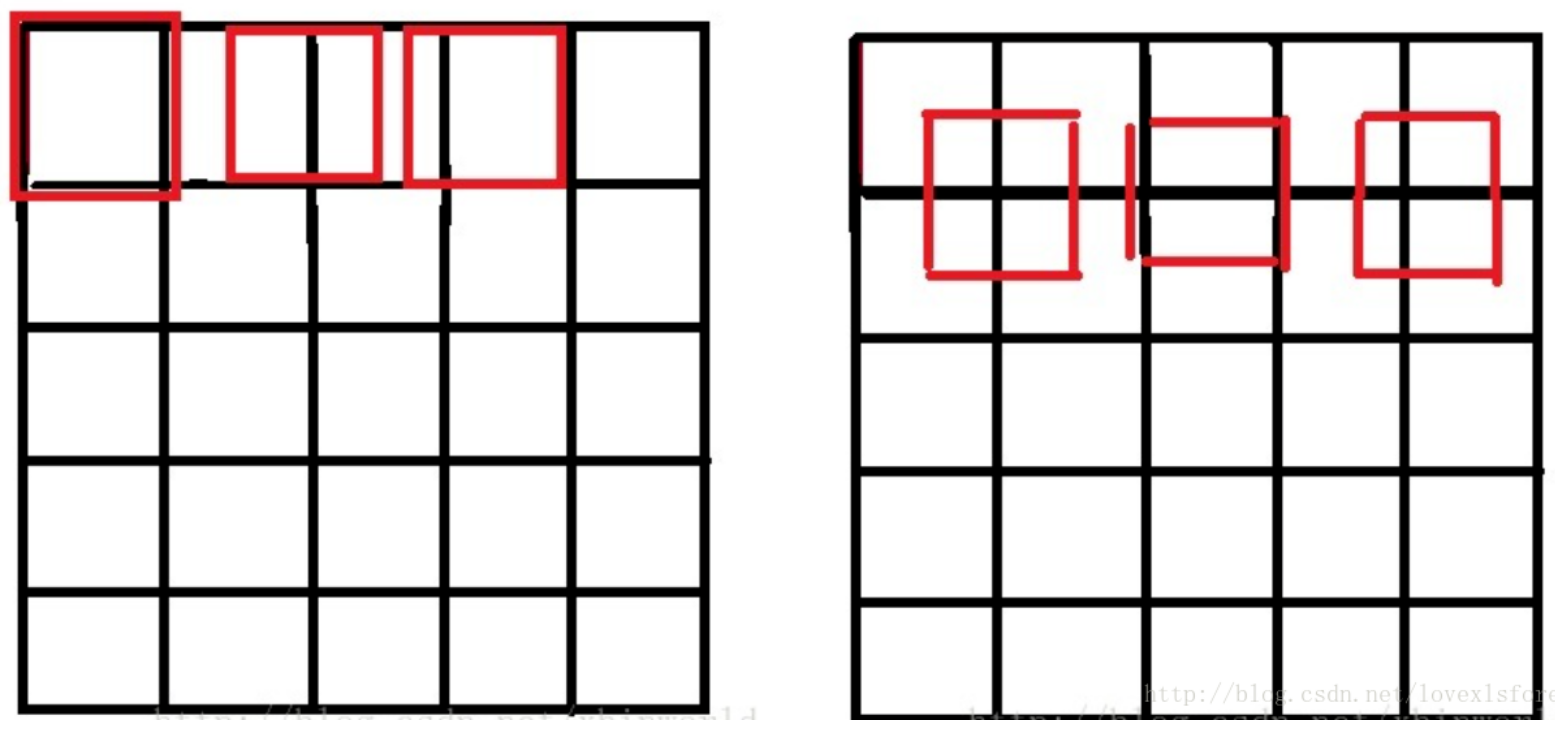
SrcY=(dstY + 0.5) * (srcHeight/dstHeight) - 0.5源图像和目标图像的原点(0,0)均选择左上角,然后根据插值公式计算目标图像每点像素,假设你需要将一幅5x5的图像缩小成3x3,那么源图像和目标图像各个像素之间的对应关系如下。如果没有这个中心对齐,根据基本公式去算,就会得到左边这样的结果;而用了对齐,就会得到右边的结果:
双立方插值
邻域像素再取样插值
lanczos插值
图像的旋转
旋转矩阵的计算原理参考:


实现方法:
采用反向映射。即从旋转后的图像出发,找到对应的原图像的点,然后将原图像中的灰度值传递过来即可,这样旋转后的图像的每个像素肯定可以对应到原图像中的一个点。
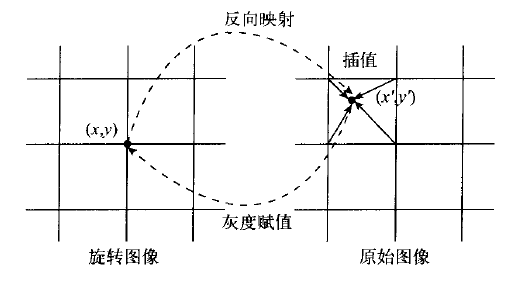
采用不同的策略算法可以使像素更加准确,*具体参照图像缩放中的各种插值法,在旋转中是同理。
直线拟合

这里只记录最常用的一种:最小二乘拟合算法
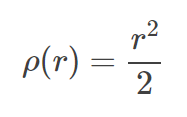
这种方法是以距离平方和为拟合判据,运行速度也最快。但是这个算法也有个很大的问题,就是当干扰点离直线较远时,一个干扰点就可能将整条拟合直线拉偏了。简单的说就是对干扰点的鲁棒性不够。
代码实现
假设直线表达式为:y = ax + b,a表示斜率,b表示截距。
对于等精度测量所得到的N组数据(xi,yi),i=1,2……,N,其中xi值被认为是准确的,所有的误差只联系着yi;用最小二乘法估计参数时,要求观测值yi的偏差的加权平方和为最小。对于等精度观测值的直线拟合来说,可使下式的值最小:
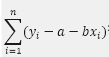
令上式等于D,并分别对a,b求一阶偏导数:
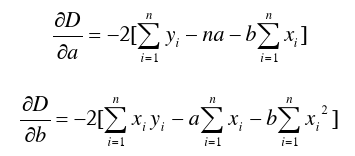
再求二阶偏导数:

很显然二阶偏导数均为非负数,于是令一阶偏导数等于0,解得a和b:
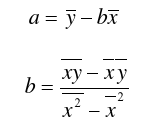
若要转化成方向向量:
因为方向向量长度为1且起点为原点,所以易得:x^2 + a * x^2 = 1,解得:
**x = 1 / sqrt( a^2 + 1 ) **
**y = a / sqrt( a^2 + 1 ) ** 即为方向向量。
opencv库
安装与编译
下载
1.在GitHub上下载了opencv4.1.1的库,并在Ubuntu中解压
2.下载 ippicv_2019_lnx_intel64_general_20180723,这个压缩包无需解压
3.将opencv-4.1.1/3rdparty/ippicv/ippicv.cmake文件中倒数第十行(以http开头的)修改成”file://path“, path为下载的ippicv_2019_lnx_intel64_general_20180723在你的电脑中存放的位置(绝对路径)
安装依赖包
sudo apt-get install build-essential
sudo apt-get install cmake git libgtk2.0-dev pkg-config libavcodec-dev libavformat-dev libswscale-dev
sudo apt-get install python-dev python-numpy libtbb2 libtbb-dev libjpeg-dev libpng-dev libtiff-dev libjasper-dev libdc1394-22-dev编译opencv
在opencv-4.1.1路径下
mkdir build
cd build
cmake -D CMAKE_BUILD_TYPE=Release -D CMAKE_INSTALL_PREFIX=/usr/local -D OPENCV_GENERATE_PKGCONFIG=ON ..
// 这里选择安装路径为/usr/local下,并开启了pkg-config
// 因为opencv4开始就不会主动支持pkg-config了,但是编译还是需要这个。
// 一定注意这两个点“..”,这是选择编译的内容为整个opencv文件夹
// 编译结束后进入下一步:
make -j8
// 这一步比较久一点,8为选择编译时使用的内核数
sudo make install
opencv_version
//编译结束后运行,若能查看到版本号就ok了
sudo gedit /etc/ld.so.conf.d/opencv.conf
//设置opencv的环境变量。(文件可能为空,即原来不存在,新建立的)
//将如下内容添加到最后:
/usr/local/lib (依然要对应成你本身的路径,这个看看安装好之后,你的安装路径下的lib文件夹位置)
//配置库
sudo ldconfig
//更改环境变量:
sudo gedit /etc/bash.bashrc
//在文件后添加
PKG_CONFIG_PATH=$PKG_CONFIG_PATH:/home/ubun/myinstall/lib/pkgconfig
export PKG_CONFIG_PATHopencv 编译后主要文件位于 /usr/local/bin /usr/local/include/opencv4 /usr/local/lib
导入opencv扩展包
1.下载opencv_contrib-4.1.1扩展包
2.将文件夹解压至opencv-4.1.1文件夹下,同时删除其下的build文件夹(之前的编译文件)
3.下载可能缺少的.i文件(会导致编译失败)
将下载的.i文件放至**/opencv_4.1.1/opencv_contrib-4.1.1/modules/xfeatures2d/src/**目录下
4.按照上一节的步骤重新编译,其中编译命令做一点改动(增加一句)
cmake -D CMAKE_BUILD_TYPE=Release -D CMAKE_INSTALL_PREFIX=/usr/local -D OPENCV_EXTRA_MODULES_PATH=/home/shenzihan/opencv-4.1.1/opencv_contrib-4.1.1/modules/ -D OPENCV_GENERATE_PKGCONFIG=ON ..5.在执行make -j4时可能会报错:fatal error: features2d/test/test_detectors_regression.impl.hpp: No such file or directory
按照内容,将opencv-4.1.1/modules/下的features2d文件夹复制到build文件夹下即可。
移植opencv
总体流程
1.封装函数
需求的操作系统环境下,只允许int char等基本类型的数据类型,因此需要将opencv库中定义的类型(如Mat)做一个转换。函数的输入不再是Mat而是转化成unsigned char和int。
也就是需要在每个opencv函数外面套一层壳,先将unsigned char和int 转为Mat CPoint等输入opencv函数,返回值再转回unsigned char和int作为移植函数的返回值,即可。
2.生成.so动态链接库
编译写好的移植函数生成.so文件:
g++ -fpic -shared -o target.so source.cpp `pkg-config --cflags --libs opencv4` -std=c++11一步到位,直接生成.so文件
3.在测试文件中调用so文件测试功能
void * LdSoHandle=dlopen("./target.so", RTLD_NOW|RTLD_GLOBAL);4.编译测试文件生成可执行文件
g++ -std=c++11 main.cpp -o mai `pkg-config --cflags --libs opencv4` -ldl
// -ldl一定要加上opencv图像类型参数的值
| 类型 | int值 | elemSize() |
|---|---|---|
| CV_8UC1 | 0 | 1 |
| CV_8UC2 | 8 | 2 |
| CV_8UC3 | 16 | 3 |
| CV_32FC1 | 5 | 4 |
| CV_32FC2 | 13 | 8 |
| CV_32FC3 | 21 | 12 |
| CV_16FC1 | 7 | 2 |
| CV_16FC2 | 15 | 4 |
| CV_16FC3 | 23 | 6 |


